
Automatic translation of speech from one language to speech in another language, called speech-to-speech translation (S2ST), is important for breaking down the communication barriers between people speaking different languages. Conventionally, automatic S2ST systems are built with a cascade of automatic speech recognition (ASR), text-to-text machine translation (MT), and text-to-speech (TTS) synthesis sub-systems, so that the system overall is text-centric. Recently, work on S2ST that doesn’t rely on intermediate text representation is emerging, such as end-to-end direct S2ST (e.g., Translatotron) and cascade S2ST based on learned discrete representations of speech (e.g., Tjandra et al.). While early versions of such direct S2ST systems obtained lower translation quality compared to cascade S2ST models, they are gaining traction as they have the potential both to reduce translation latency and compounding errors, and to better preserve paralinguistic and non-linguistic information from the original speech, such as voice, emotion, tone, etc. However, such models usually have to be trained on datasets with paired S2ST data, but the public availability of such corpora is extremely limited.
To foster research on such a new generation of S2ST, we introduce a Common Voice-based Speech-to-Speech translation corpus, or CVSS, which includes sentence-level speech-to-speech translation pairs from 21 languages into English. Unlike existing public corpora, CVSS can be directly used for training such direct S2ST models without any extra processing. In “CVSS Corpus and Massively Multilingual Speech-to-Speech Translation”, we describe the dataset design and development, and demonstrate the effectiveness of the corpus through training of baseline direct and cascade S2ST models and showing performance of a direct S2ST model that approaches that of a cascade S2ST model.
Building CVSS
CVSS is directly derived from the CoVoST 2 speech-to-text (ST) translation corpus, which is further derived from the Common Voice speech corpus. Common Voice is a massively multilingual transcribed speech corpus designed for ASR in which the speech is collected by contributors reading text content from Wikipedia and other text corpora. CoVoST 2 further provides professional text translation for the original transcript from 21 languages into English and from English into 15 languages. CVSS builds on these efforts by providing sentence-level parallel speech-to-speech translation pairs from 21 languages into English (shown in the table below).
To facilitate research with different focuses, two versions of translation speech in English are provided in CVSS, both are synthesized using state-of-the-art TTS systems, with each version providing unique value that doesn’t exist in other public S2ST corpora:
CVSS-C: All the translation speech is in a single canonical speaker’s voice. Despite being synthetic, the speech is highly natural, clean, and consistent in speaking style. These properties ease the modeling of the target speech and enable trained models to produce high quality translation speech suitable for general user-facing applications where speech quality is of higher importance than accurately reproducing the speakers’ voices. CVSS-T: The translation speech captures the voice from the corresponding source speech. Each S2ST pair has a similar voice on the two sides, despite being in different languages. Because of this, the dataset is suitable for building models where accurate voice preservation is desired, such as for movie dubbing.
Together with the source speech, the two S2ST datasets contain 1,872 and 1,937 hours of speech, respectively.
Source
Language Code Source
speech (X) CVSS-C
target speech (En) CVSS-T
target speech (En) French fr 309.3 200.3 222.3 German de 226.5 137.0 151.2 Catalan ca 174.8 112.1 120.9 Spanish es 157.6 94.3 100.2 Italian it 73.9 46.5 49.2 Persian fa 58.8 29.9 34.5 Russian ru 38.7 26.9 27.4 Chinese zh 26.5 20.5 22.1 Portuguese pt 20.0 10.4 11.8 Dutch nl 11.2 7.3 7.7 Estonian et 9.0 7.3 7.1 Mongolian mn 8.4 5.1 5.7 Turkish tr 7.9 5.4 5.7 Arabic ar 5.8 2.7 3.1 Latvian lv 4.9 2.6 3.1 Swedish sv 4.3 2.3 2.8 Welsh cy 3.6 1.9 2.0 Tamil ta 3.1 1.7 2.0 Indonesian id 3.0 1.6 1.7 Japanese ja 3.0 1.7 1.8 Slovenian sl 2.9 1.6 1.9 Total 1,153.2 719.1 784.2 Amount of source and target speech of each X-En pair in CVSS (hours).
In addition to translation speech, CVSS also provides normalized translation text matching the pronunciation in the translation speech (on numbers, currencies, acronyms, etc., see data samples below, e.g., where “100%” is normalized as “one hundred percent” or “King George II” is normalized as “king george the second”), which can benefit both model training as well as standardizing the evaluation.
CVSS is released under the Creative Commons Attribution 4.0 International (CC BY 4.0) license and it can be freely downloaded online.
Data Samples
Example 1: Source audio (French) Source transcript (French) Le genre musical de la chanson est entièrement le disco. CVSS-C translation audio (English) CVSS-T translation audio (English) Translation text (English) The musical genre of the song is 100% Disco. Normalized translation text (English) the musical genre of the song is one hundred percent disco Example 2:Source audio (Chinese) Source transcript (Chinese) 弗雷德里克王子,英国王室成员,为乔治二世之孙,乔治三世之幼弟。 CVSS-C translation audio (English) CVSS-T translation audio (English) Translation text (English) Prince Frederick, member of British Royal Family, Grandson of King George II, brother of King George III. Normalized translation text (English) prince frederick member of british royal family grandson of king george the second brother of king george the third
Baseline Models
On each version of CVSS, we trained a baseline cascade S2ST model as well as two baseline direct S2ST models and compared their performance. These baselines can be used for comparison in future research.
Cascade S2ST: To build strong cascade S2ST baselines, we trained an ST model on CoVoST 2, which outperforms the previous states of the art by +5.8 average BLEU on all 21 language pairs (detailed in the paper) when trained on the corpus without using extra data. This ST model is connected to the same TTS models used for constructing CVSS to compose very strong cascade S2ST baselines (ST → TTS).
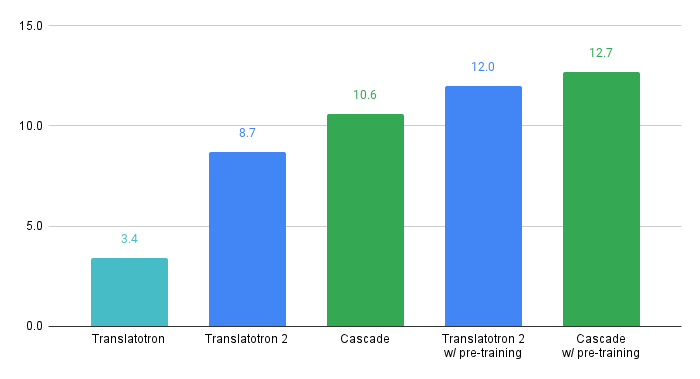
Direct S2ST: We built two baseline direct S2ST models using Translatotron and Translatotron 2. When trained from scratch with CVSS, the translation quality from Translatotron 2 (8.7 BLEU) approaches that of the strong cascade S2ST baseline (10.6 BLEU). Moreover, when both use pre-training the gap decreases to only 0.7 BLEU on ASR transcribed translation. These results verify the effectiveness of using CVSS to train direct S2ST models.
Translation quality of baseline direct and cascade S2ST models built on CVSS-C, measured by BLEU on ASR transcription from speech translation. The pre-training was done on CoVoST 2 without other extra data sets.
{kind=link}
Conclusion
We have released two versions of multilingual-to-English S2ST datasets, CVSS-C and CVSS-T, each with about 1.9K hours of sentence-level parallel S2ST pairs, covering 21 source languages. The translation speech in CVSS-C is in a single canonical speaker’s voice, while the same in CVSS-T is in voices transferred from the source speech. Each of these datasets provides unique value not existing in other public S2ST corpora.
We built baseline multilingual direct S2ST models and cascade S2ST models on both datasets, which can be used for comparison in future works. To build strong cascade S2ST baselines, we trained an ST model on CoVoST 2, which outperforms the previous states of the art by +5.8 average BLEU when trained on the corpus without extra data. Nevertheless, the performance of the direct S2ST models approaches the strong cascade baselines when trained from scratch, and with only 0.7 BLEU difference on ASR transcribed translation when utilized pre-training. We hope this work helps accelerate the research on direct S2ST.
Acknowledgments
We acknowledge the volunteer contributors and the organizers of the Common Voice and LibriVox projects for their contribution and collection of recordings, the creators of Common Voice, CoVoST, CoVoST 2, Librispeech and LibriTTS corpora for their previous work. The direct contributors to the CVSS corpus and the paper include Ye Jia, Michelle Tadmor Ramanovich, Quan Wang, Heiga Zen. We also thank Ankur Bapna, Yiling Huang, Jason Pelecanos, Colin Cherry, Alexis Conneau, Yonghui Wu, Hadar Shemtov and Françoise Beaufays for helpful discussions and support.