
Automatic Speech Recognition - An Overview
An overview of how Automatic Speech Recognition systems work and some of the challenges.
See more on this video at https://www.microsoft.com/en-us/research/video/automatic-speech-recognition-overview/
See more on this video at https://www.microsoft.com/en-us/research/video/automatic-speech-recognition-overview/

Automatic Speech Recognition - An Overview
An overview of how Automatic Speech Recognition systems work and some [...]

Deep Learning for Speech Recognition (Adam Coates, Baidu)
The talks at the Deep Learning School on September 24/25, 2016 were [...]

The Eleventh HOPE (2016): Coding by Voice with Open Source Speech Recognition
Friday, July 22, 2016: 8:00 pm (Friedman): Carpal tunnel and [...]

Speech Emotion Recognition with Convolutional Neural Networks
Speech emotion recognition promises to play an important role in [...]

Automatic Speech Recognition: An Overview
A. Madhavaraj
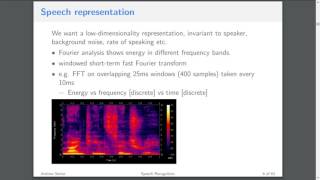
Lecture 9 - Speech Recognition (ASR) [Andrew Senior]
Automatic Speech Recognition (ASR) is the task of transducing raw [...]

Emotion Detection from Speech Signals
Despite the great progress made in artificial intelligence, we are [...]

Speech Recognition Breakthrough for the Spoken, Translated Word
Chief Research Officer Rick Rashid demonstrates a speech recognition [...]

Speech signals separation with microphone array
Separating simultaneous speech signals from a mixture is well studied [...]

Automatic Speech Emotion Recognition Using Recurrent Neural Networks with Local Attention
Automatic emotion recognition from speech is a challenging task which [...]
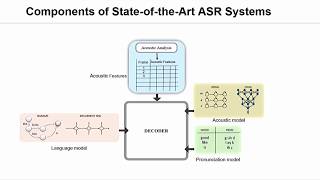
State-of-the-Art in Speech Technologies
The Academic Research Summit, co-organized by Microsoft Research and [...]

Real-time Single-channel Speech Enhancement with Recurrent Neural Networks
Single-channel speech enhancement using deep neural networks (DNNs) [...]

Distant Speech Recognition: No Black Boxes Allowed
A complete system for distant speech recognition (DSR) typically [...]

Emotion Recognition in Speech Signal: Experimental Study, Development and Applications
In this talk I will overview my research on emotion expression and [...]

Towards Robust Conversational Speech Recognition and Understanding
While significant progress has been made in automatic speech [...]

Spontaneous Speech: Challenges and Opportunities for Parsing
Recent advances in automatic speech recognition (ASR) provide new [...]

Some Recent Advances in Gaussian Mixture Modeling for Speech Recognition
State-of-the-art Hidden Markov Model (HMM) based speech recognition [...]

High-Accuracy Neural-Network Models for Speech Enhancement
In this talk we will discuss our recent work on AI techniques that [...]

Enriching Speech Translation: Exploiting Information Beyond Words
Current statistical speech translation approaches predominantly rely [...]

DNN-Based Online Speech Enhancement Using Multitask Learning and Suppression Rule Estimation
Most of the currently available speech enhancement algorithms use a [...]

Microphone array signal processing: beyond the beamformer
Array signal processing is a well-established area of research, [...]

Blind Multi-Microphone Noise Reduction and Dereverberation Algorithms
Blind Multi-Microphone Noise Reduction and Dereverberation Algorithms [...]

Exploring Richer Sequence Models in Speech and Language Processing
Conditional and other feature-based models have become an increasingly [...]

Dereverberation Suppression for Improved Speech Recognition and Human Perception
The factors that harm the speech recognition results for un-tethered [...]

Deep Neural Networks for Speech and Image Processing
Neural networks are experiencing a renaissance, thanks to a new [...]

Speech and language: the crown jewel of AI with Dr. Xuedong Huang
Episode 76 | May 15, 2019 When was the last time you had a meaningful [...]

In-Car Speech User Interfaces and their Effects on Driving Performance
Ubiquitous computing and speech user interaction are starting to play [...]

Recognizing a Million Voices: Low Dimensional Audio Representations for Speaker Identification
Recent advances in speaker verification technology have resulted in [...]

A Noise-Robust Speech Recognition Method
This presentation proposes a noise-robust speech recognition method [...]

HMM-based Speech Synthesis: Fundamentals and Its Recent Advances
The task of speech synthesis is to convert normal language text into [...]

Should Machines Emulate Human Speech Recognition?
Machine-based, automatic speech recognition (ASR) systems decode the [...]

New Directions in Robust Automatic Speech Recognition
As speech recognition technology is transferred from the laboratory to [...]

Rapid Language Portability for Speech Processing Systems
With the growing demand for speech processing systems in many [...]

Making Voicebots Work for Accents
Voice-driven automated agents such as personal assistants are becoming [...]

Multi-rate neural networks for efficient acoustic modeling
In sequence recognition, the problem of long-span dependency in input [...]

Speaker Diarization: Optimal Clustering and Learning Speaker Embeddings
Speaker diarization consist of automatically partitioning an input [...]

Frontiers in Speech and Language
The last few years have witnessed a renaissance in multiple areas of [...]

Towards Spoken Term Discovery at Scale with Zero Resources
The spoken term discovery task takes speech as input and identifies [...]

Multi-microphone Dereverberation and Intelligibility Estimation in Speech Processing
When speech signals are captured by one or more microphones in [...]

Soft Margin Estimation for Automatic Speech Recognition
In this study, a new discriminative learning framework, called soft [...]

A Smartphone as Your Third Ear
: We humans are capable of remembering, recognizing, and acting upon [...]

Redesiging Neural Architectures for Sequence to Sequence Learning
The Encoder-Decoder model with soft-attention is now the defacto [...]

Tutorial: Deep Learning
Deep Learning allows computational models composed of multiple [...]

Modeling high-dimensional sequences with recurrent neural networks
Humans commonly understand sequential events by giving importance to [...]

Reformulating the HMM as a trajectory model
A trajectory model, derived from the HMM by imposing explicit [...]

Lattice-Based Discriminative Training: Theory and Practice
Lattice-based discriminative training techniques such as MMI and MPE [...]

A Directionally Tunable but Frequency-Invariant Beamformer for an “Acoustic Velocity-Sensor Triad”
"A Directionally Tunable but Frequency-Invariant Beamformer for an [...]

Symposium: Deep Learning - Alex Graves
Neural Turing Machines - Alex Graves
NIPS: Oral Session 4 - Ilya Sutskever
Sequence to Sequence Learning with Neural Networks Deep Neural [...]

HDSI Unsupervised Deep Learning Tutorial - Alex Graves
Filmed on day two of the 2019 HDSI Conference
More Videos