
The question of how to compile faster and smaller code arose together with the birth of modem computers. Better code optimization can significantly reduce the operational cost of large datacenter applications. The size of compiled code matters the most to mobile and embedded systems or software deployed on secure boot partitions, where the compiled binary must fit in tight code size budgets. With advances in the field, the headroom has been heavily squeezed with increasingly complicated heuristics, impeding maintenance and further improvements.
Recent research has shown that machine learning (ML) can unlock more opportunities in compiler optimization by replacing complicated heuristics with ML policies. However, adopting ML in general-purpose, industry-strength compilers remains a challenge.
To address this, we introduce “MLGO: a Machine Learning Guided Compiler Optimizations Framework”, the first industrial-grade general framework for integrating ML techniques systematically in LLVM (an open-source industrial compiler infrastructure that is ubiquitous for building mission-critical, high-performance software). MLGO uses reinforcement learning (RL) to train neural networks to make decisions that can replace heuristics in LLVM. We describe two MLGO optimizations for LLVM: 1) reducing code size with inlining; and 2) improving code performance with register allocation (regalloc). Both optimizations are available in the LLVM repository, and have been deployed in production.
How Does MLGO Work? With Inlining-for-Size As a Case Study
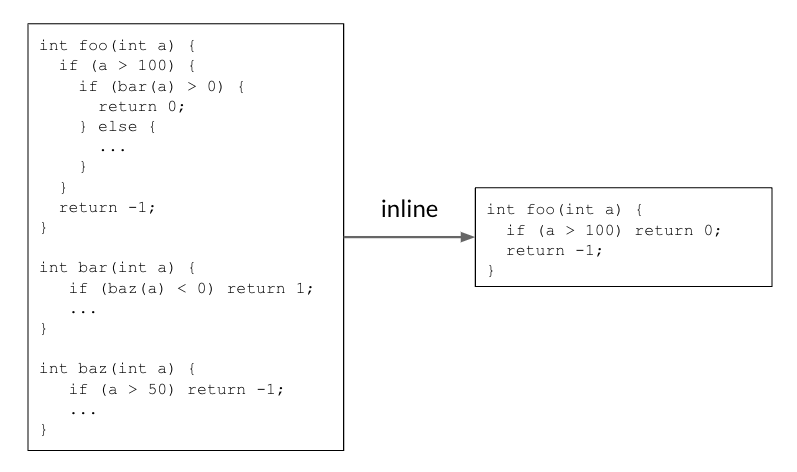
Inlining helps reduce code size by making decisions that enable the removal of redundant code. In the example below, the caller function foo() calls the callee function bar(), which itself calls baz(). Inlining both callsites returns a simple foo() function that reduces the code size.
Inlining reduces code size by removing redundant code.
{kind=link}
In real code, there are thousands of functions calling each other, and thus comprise a call graph. During the inlining phase, the compiler traverses over the call graph on all caller-callee pairs, and makes decisions on whether to inline a caller-callee pair or not. It is a sequential decision process as previous inlining decisions will alter the call graph, affecting later decisions and the final result. In the example above, the call graph foo() → bar() → baz() needs a “yes” decision on both edges to make the code size reduction happen.
Before MLGO, the inline / no-inline decision was made by a heuristic that, over time, became increasingly difficult to improve. MLGO substitutes the heuristic with an ML model. During the call graph traversal, the compiler seeks advice from a neural network on whether to inline a particular caller-callee pair by feeding in relevant features (i.e., inputs) from the graph, and executes the decisions sequentially until the whole call graph is traversed.
Illustration of MLGO during inlining. “#bbs”, “#users”, and “callsite height” are example caller-callee pair features.
{kind=link}
MLGO trains the decision network (policy) with RL using policy gradient and evolution strategies algorithms. While there is no ground truth about best decisions, online RL iterates between training and running compilation with the trained policy to collect data and improve the policy. In particular, given the current model under training, the compiler consults the model for inline / no-inline decision making during the inlining stage. After the compilation finishes, it produces a log of the sequential decision process (state, action, reward). The log is then passed to the trainer to update the model. This process repeats until we obtain a satisfactory model.
Compiler behavior during training. The compiler compiles the source code foo.cpp to an object file foo.o with a sequence of optimization passes, one of which is the inline pass.
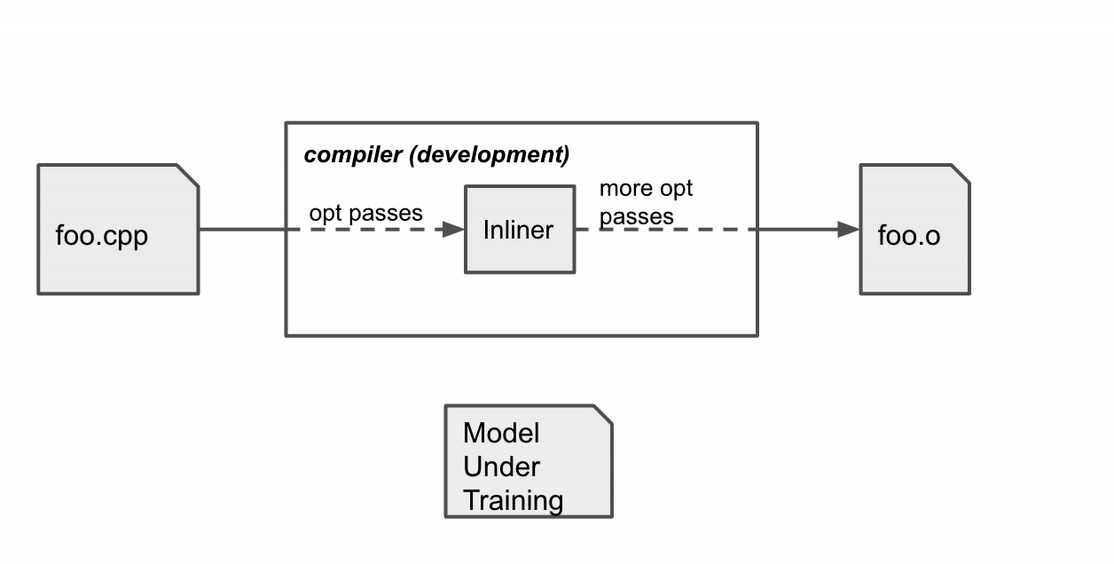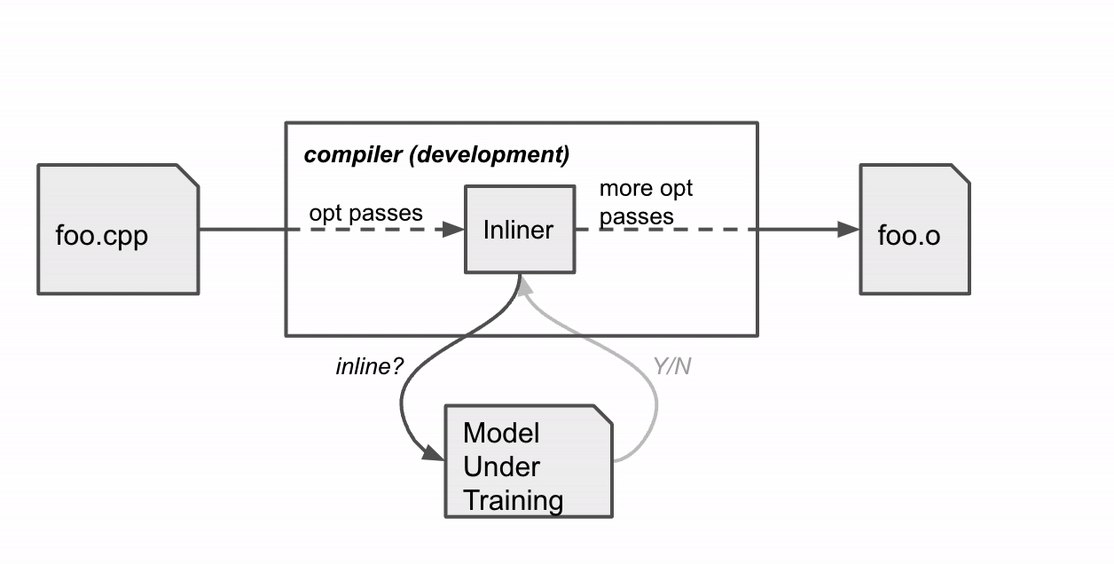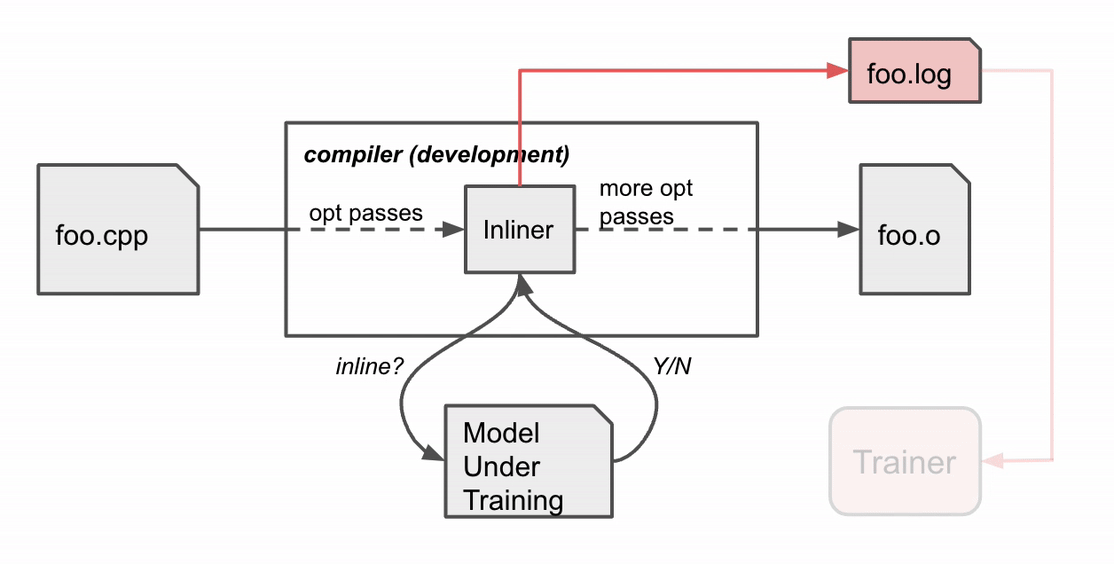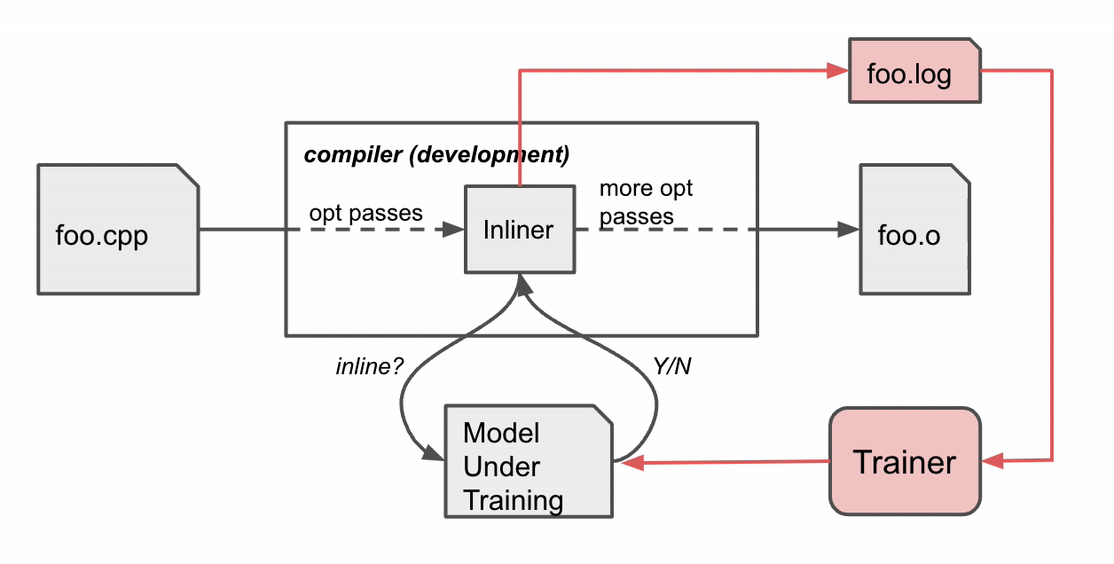{kind=link}
The trained policy is then embedded into the compiler to provide inline / no-inline decisions during compilation. Unlike the training scenario, the policy does not produce a log. The TensorFlow model is embedded with XLA AOT, which converts the model into executable code. This avoids TensorFlow runtime dependency and overhead, minimizing the extra time and memory cost introduced by ML model inference at compilation time.
Compiler behavior in production.
{kind=link}
We trained the inlining-for-size policy on a large internal software package containing 30k modules. The trained policy is generalizable when applied to compile other software and achieves a 3% ~ 7% size reduction. In addition to the generalizability across software, generalizability across time is also important — both the software and compiler are under active development so the trained policy needs to retain good performance for a reasonable time. We evaluated the model’s performance on the same set of software three months later and found only slight degradation.
Inlining-for-size policy size reduction percentages. The x-axis presents different software and the y-axis represents the percentage size reduction. “Training” is the software on which the model was trained and “Infra[1|2|3]” are different internal software packages.
{kind=link}
The MLGO inlining-for-size training has been deployed on Fuchsia — a general purpose open source operating system designed to power a diverse ecosystem of hardware and software, where binary size is critical. Here, MLGO showed a 6.3% size reduction for C++ translation units.
Register-Allocation (for performance)
As a general framework, we used MLGO to improve the register allocation pass, which improves the code performance in LLVM. Register Allocation solves the problem of assigning physical registers to live ranges (i.e., variables).
As the code executes, different live ranges are completed at different times, freeing up registers for use by subsequent processing stages. In the example below, each “add” and “multiply” instruction requires all operands and the result to be in physical registers. The live range x is allocated to the green register and is completed before either live ranges in the blue or yellow registers. After x is completed, the green register becomes available and is assigned to live range t.
{kind=link}
When it’s time to allocate live range q, there are no available registers, so the register allocation pass must decide which (if any) live range can be “evicted” from its register to make room for q. This is referred to as the “live range eviction” problem, and is the decision for which we train the model to replace original heuristics. In this particular example, it evicts z from the yellow register, and assigns it to q and the first half of z.
We now consider the unassigned second half of live range z. We have a conflict again, and this time the live range t is evicted and split, and the first half of t and the final part of z end up using the green register. The middle part of z corresponds to the instruction q = t * y, where z is not being used, so it is not assigned to any register and its value is stored in the stack from the yellow register, which later gets reloaded to the green register. The same happens to t. This adds extra load/store instructions to the code and degrades performance. The goal of the register allocation algorithm is to reduce such inefficiencies as much as possible. This is used as the reward to guide RL policy training.
Similar to the inlining-for-size policy, the register allocation (regalloc-for-performance) policy is trained on a large Google internal software package, and is generalizable across different software, with 0.3% ~1.5% improvements in queries per second (QPS) on a set of internal large-scale datacenter applications. The QPS improvement has persisted for months after its deployment, showing the model’s generalizability across the time horizon.
Conclusion and Future Work
We propose MLGO, a framework for integrating ML techniques systematically in an industrial compiler, LLVM. MLGO is a general framework that can be expanded to be: 1) deeper, e.g., adding more features, and applying better RL algorithms; and 2) broader, by applying it to more optimization heuristics beyond inlining and regalloc. We are enthusiastic about the possibilities MLGO can bring to the compiler optimization domain and look forward to its further adoption and to future contributions from the research community.
Try it Yourself
Check out the open-sourced end-to-end data collection and training solution on github and a demo that uses policy gradient to train an inlining-for-size policy.
Acknowledgements
We’d like to thank MLGO’s contributors and collaborators Eugene Brevdo, Jacob Hegna, Gaurav Jain, David Li, Zinan Lin, Kshiteej Mahajan, Jack Morris, Girish Mururu, Jin Xin Ng, Robert Ormandi, Easwaran Raman, Ondrej Sykora, Maruf Zaber, Weiye Zhao. We would also like to thank Petr Hosek, Yuqian Li, Roland McGrath, Haowei Wu for trusting us and deploying MLGO in Fuchsia as MLGO’s very first customer; thank David Blaikie, Eric Christopher, Brooks Moses, Jordan Rupprecht for helping to deploy MLGO in Google internal large-scale datacenter applications; and thank Ed Chi, Tipp Moseley for their leadership support.