
Advances in computer vision and natural language processing continue to unlock new ways of exploring billions of images available on public and searchable websites. Today’s visual search tools make it possible to search with your camera, voice, text, images, or multiple modalities at the same time. However, it remains difficult to input subjective concepts, such as visual tones or moods, into current systems. For this reason, we have been working collaboratively with artists, photographers, and image researchers to explore how machine learning (ML) might enable people to use expressive queries as a way of visually exploring datasets.
Today, we are introducing Mood Board Search, a new ML-powered research tool that uses mood boards as a query over image collections. This enables people to define and evoke visual concepts on their own terms. Mood Board Search can be useful for subjective queries, such as “peaceful”, or for words and individual images that may not be specific enough to produce useful results in a standard search, such as “abstract details in overlooked scenes” or “vibrant color palette that feels part memory, part dream“. We developed, and will continue to develop, this research tool in alignment with our AI Principles.
Search Using Mood Boards
With Mood Board Search, our goal is to design a flexible and approachable interface so people without ML expertise can train a computer to recognize a visual concept as they see it. The tool interface is inspired by mood boards, commonly used by people in creative fields to communicate the “feel” of an idea using collections of visual materials.
With Mood Board Search, users can train a computer to recognize visual concepts in image collections.
{kind=link}
To get started, simply drag and drop a small number of images that represent the idea you want to convey. Mood Board Search returns the best results when the images share a consistent visual quality, so results are more likely to be relevant with mood boards that share visual similarities in color, pattern, texture, or composition.
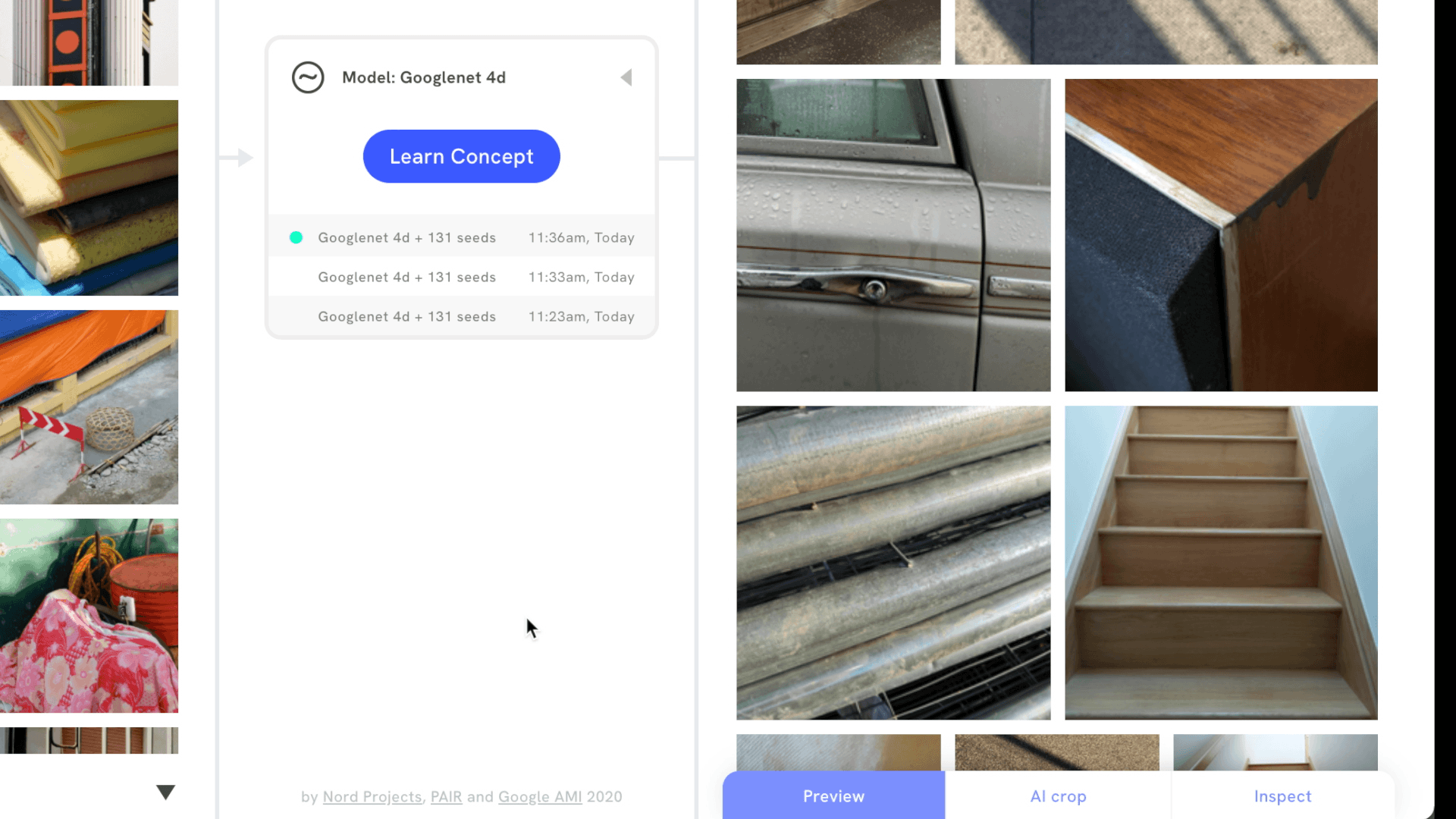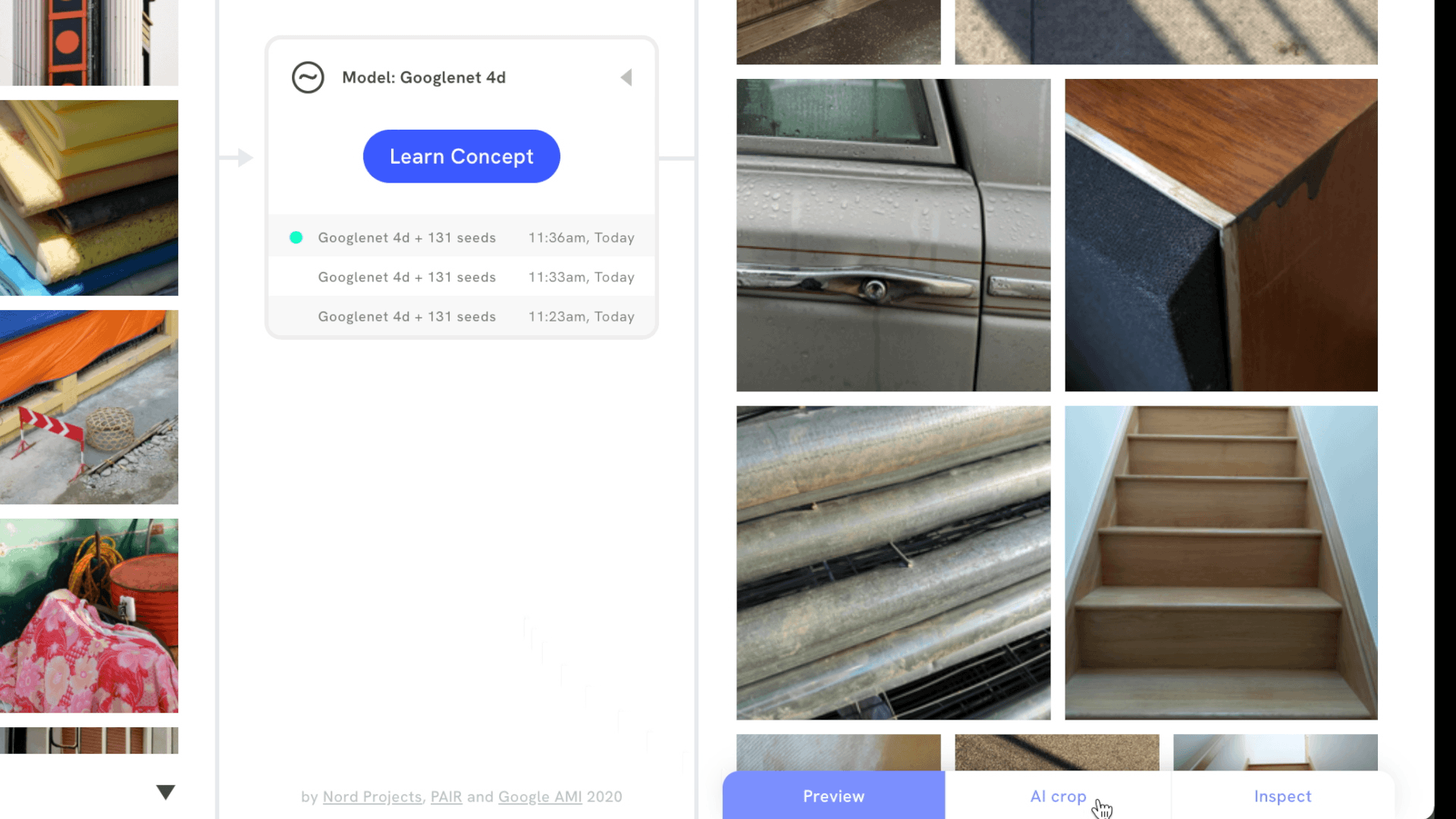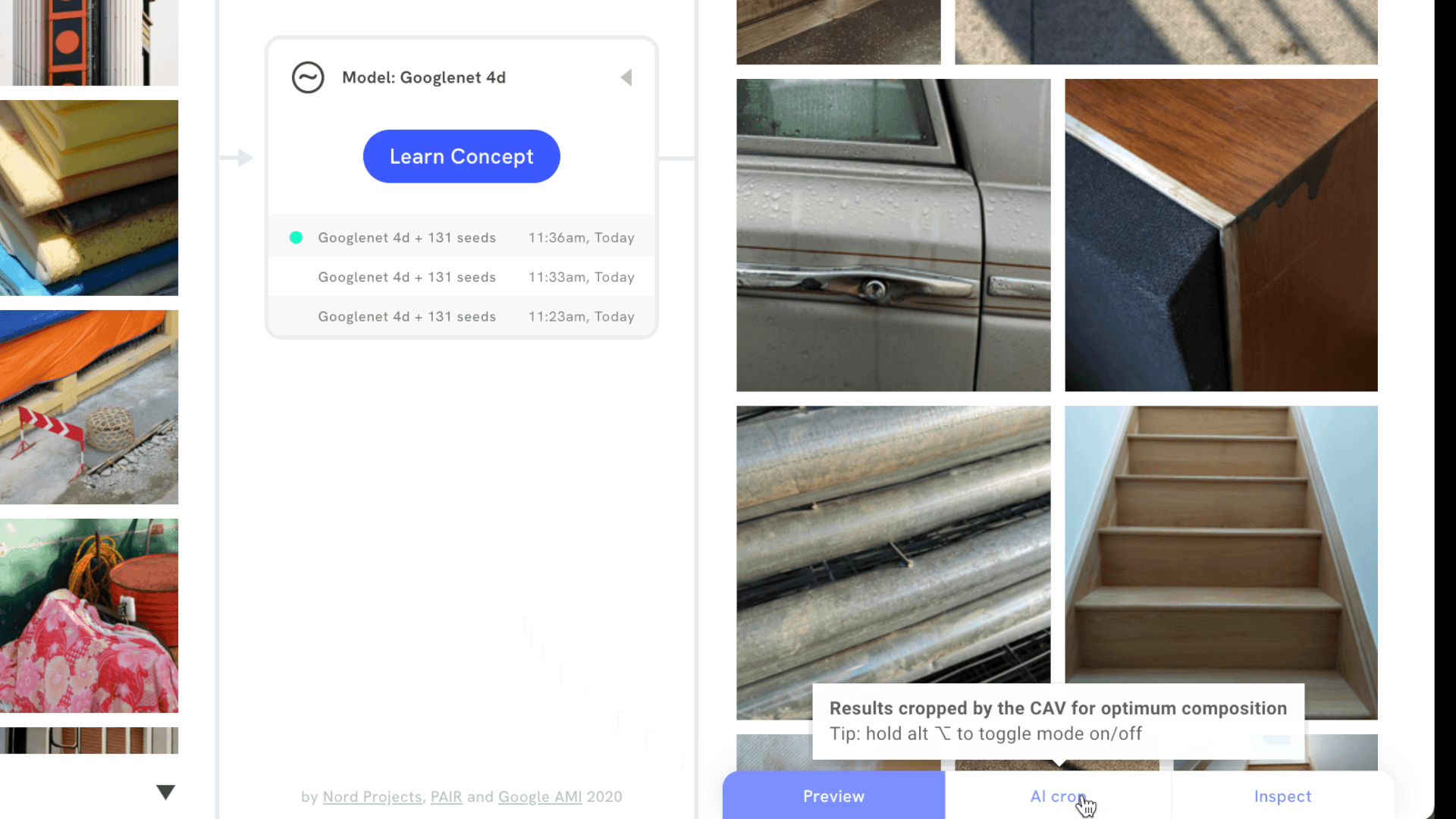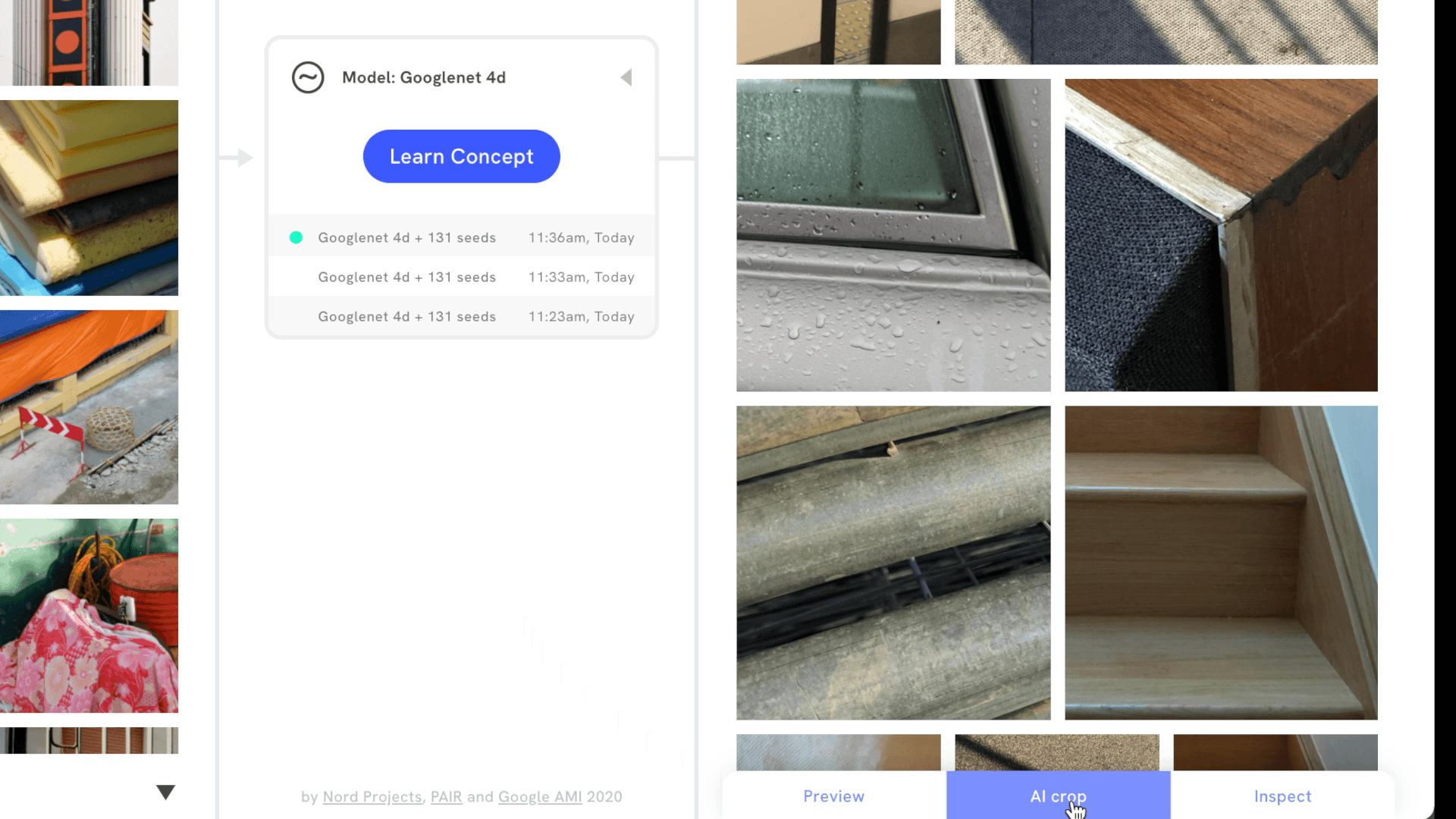
It’s also possible to signal which images are more important to a visual concept by upweighting or downweighting images, or by adding images that are the opposite of the concept. Then, users can review and inspect search results to understand which part of an image best matches the visual concept. Focus mode does this by revealing a bounding box around part of the image, while AI crop cuts in directly, making it easier to draw attention to new compositions.
Supported interactions, like AI crop, allow users to see which part of an image best matches their visual concept.
{kind=link}
Powered by Concept Activation Vectors (CAVs)
Mood Board Search takes advantage of pre-trained computer vision models, such as GoogLeNet and MobileNet, and a machine learning approach called Concept Activation Vectors (CAVs).
CAVs are a way for machines to represent images (what we understand) using numbers or directions in a neural net’s embedding space (which can be thought of as what machines understand). CAVs can be used as part of a technique, Testing with CAVs (TCAV), to quantify the degree to which a user-defined concept is important to a classification result; e.g., how sensitive a prediction of “zebra” is to the presence of stripes. This is a research approach we open-sourced in 2018, and the work has since been widely applied to medical applications and science to build ML applications that can provide better explanations for what machines see. You can learn more about embedding vectors in general in this Google AI blog post, and our approach to working with TCAVs in Been Kim’s Keynote at ICLR.
In Mood Board Search, we use CAVs to find a model’s sensitivity to a mood board created by the user. In other words, each mood board creates a CAV — a direction in embedding space — and the tool searches an image dataset, surfacing images that are the closest match to the CAV. However, the tool takes it one step further, by segmenting each image in the dataset in 15 different ways, to uncover as many relevant compositions as possible. This is the approach behind features like Focus mode and AI crop.
Three artists created visual concepts to share their way of seeing, shown here in an experimental app by design invention studio, Nord Projects.
{kind=link}
Because embedding vectors can be learned and re-used across models, tools like Mood Board Search can help us express our perspective to other people. Early collaborations with creative communities have shown value in being able to create and share subjective experiences with others, resulting in feelings of being able to “break out of visually-similar echo chambers” or “see the world through another person’s eyes”. Even misalignment between model and human understanding of a concept frequently resulted in unexpected and inspiring connections for collaborators. Taken together, these findings point towards new ways of designing collaborative ML systems that embrace personal and collective subjectivity.
Conclusions and Future Work
Today, we’re open-sourcing the code to Mood Board Search, including three visual concepts made by our collaborators, and a Mood Board Search Python Library for people to tap the power of CAVs directly into their own websites and apps. While these tools are early-stage prototypes, we believe this capability can have a wide-range of applications from exploring unorganized image collections to externalizing ways of seeing into collaborative and shareable artifacts. Already, an experimental app by design invention studio Nord Projects, made using Mood Board Search, investigates the opportunities for running CAVs in camera, in real-time. In future work, we plan to use Mood Board Search to learn about new forms of human-machine collaboration and expand ML models and inputs — like text and audio — to allow even deeper subjective discoveries, regardless of medium.
If you’re interested in a demo of this work for your team or organization, email us at cav-experiments-support@google.com.
Acknowledgments
This blog presents research by (in alphabetical order): Kira Awadalla, Been Kim, Eva Kozanecka, Alison Lentz, Alice Moloney, Emily Reif, and Oliver Siy, in collaboration with design invention studio Nord Projects. We thank our co-author, Eva Kozanecka, our artist collaborators, Alexander Etchells, Tom Hatton, Rachel Maggart, the Imaging team at The British Library for their participation in beta previews, and Blaise Agüera y Arcas, Jess Holbrook, Fernanda Viegas, and Martin Wattenberg for their support of this research project.