
Advanced language models (e.g., GPT, GLaM, PaLM and T5) have demonstrated diverse capabilities and achieved impressive results across tasks and languages by scaling up their number of parameters. Vision-language (VL) models can benefit from similar scaling to address many tasks, such as image captioning, visual question answering (VQA), object recognition, and in-context optical-character-recognition (OCR). Increasing the success rates for these practical tasks is important for everyday interactions and applications. Furthermore, for a truly universal system, vision-language models should be able to operate in many languages, not just one.
In “PaLI: A Jointly-Scaled Multilingual Language-Image Model”, we introduce a unified language-image model trained to perform many tasks and in over 100 languages. These tasks span vision, language, and multimodal image and language applications, such as visual question answering, image captioning, object detection, image classification, OCR, text reasoning, and others. Furthermore, we use a collection of public images that includes automatically collected annotations in 109 languages, which we call the WebLI dataset. The PaLI model pre-trained on WebLI achieves state-of-the-art performance on challenging image and language benchmarks, such as COCO-Captions, CC3M, nocaps, TextCaps, VQAv2, OK-VQA, TextVQA and others. It also outperforms prior models’ multilingual visual captioning and visual question answering benchmarks.
Overview
One goal of this project is to examine how language and vision models interact at scale and specifically the scalability of language-image models. We explore both per-modality scaling and the resulting cross-modal interactions of scaling. We train our largest model to 17 billion (17B) parameters, where the visual component is scaled up to 4B parameters and the language model to 13B.
The PaLI model architecture is simple, reusable and scalable. It consists of a Transformer encoder that processes the input text, and an auto-regressive Transformer decoder that generates the output text. To process images, the input to the Transformer encoder also includes “visual words” that represent an image processed by a Vision Transformer (ViT). A key component of the PaLI model is reuse, in which we seed the model with weights from previously-trained uni-modal vision and language models, such as mT5-XXL and large ViTs. This reuse not only enables the transfer of capabilities from uni-modal training, but also saves computational cost.
The PaLI model addresses a wide range of tasks in the language-image, language-only and image-only domain using the same API (e.g., visual-question answering, image captioning, scene-text understanding, etc.). The model is trained to support over 100 languages and tuned to perform multilingually for multiple language-image tasks.
{kind=link}
Dataset: Language-Image Understanding in 100+ Languages
Scaling studies for deep learning show that larger models require larger datasets to train effectively. To unlock the potential of language-image pretraining, we construct WebLI, a multilingual language-image dataset built from images and text available on the public web.
WebLI scales up the text language from English-only datasets to 109 languages, which enables us to perform downstream tasks in many languages. The data collection process is similar to that employed by other datasets, e.g. ALIGN and LiT, and enabled us to scale the WebLI dataset to 10 billion images and 12 billion alt-texts.
In addition to annotation with web text, we apply the Cloud Vision API to perform OCR on the images, leading to 29 billion image-OCR pairs. We perform near-deduplication of the images against the train, validation and test splits of 68 common vision and vision-language datasets, to avoid leaking data from downstream evaluation tasks, as is standard in the literature. To further improve the data quality, we score image and alt-text pairs based on their cross-modal similarity, and tune the threshold to keep only 10% of the images, for a total of 1 billion images used for training PaLI.
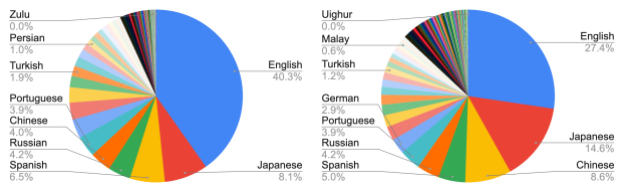
Sampled images from WebLI associated with multilingual alt-text and OCR. The second image is by jopradier (original), used under the CC BY-NC-SA 2.0 license. Remaining images are also used with permission.Statistics of recognized languages from alt-text and OCR in WebLI.Image-text pair counts of WebLI and other large-scale vision-language datasets, CLIP, ALIGN and LiT.
{kind=link}
{kind=link}
{kind=link}
Training Large Language-Image Models
Vision-language tasks require different capabilities and sometimes have diverging goals. Some tasks inherently require localization of objects to solve the task accurately, whereas some other tasks might need a more global view. Similarly, different tasks might require either long or compact answers. To address all of these objectives, we leverage the richness of the WebLI pre-training data and introduce a mixture of pre-training tasks, which prepare the model for a variety of downstream applications. To accomplish the goal of solving a wide variety of tasks, we enable knowledge-sharing between multiple image and language tasks by casting all tasks into a single generalized API (input: image + text; output: text), which is also shared with the pretraining setup. The objectives used for pre-training are cast into the same API as a weighted mixture aimed at both maintaining the ability of the reused model components and training the model to perform new tasks (e.g., split-captioning for image description, OCR prediction for scene-text comprehension, VQG and VQA prediction).
The model is trained in JAX with Flax using the open-sourced T5X and Flaxformer framework. For the visual component, we introduce and train a large ViT architecture, named ViT-e, with 4B parameters using the open-sourced BigVision framework. ViT-e follows the same recipe as the ViT-G architecture (which has 2B parameters). For the language component, we concatenate the dense token embeddings with the patch embeddings produced by the visual component, together as the input to the multimodal encoder-decoder, which is initialized from mT5-XXL. During the training of PaLI, the weights of this visual component are frozen, and only the weights of the multimodal encoder-decoder are updated.
Results
We compare PaLI on common vision-language benchmarks that are varied and challenging. The PaLI model achieves state-of-the-art results on these tasks, even outperforming very large models in the literature. For example, it outperforms the Flamingo model, which is several times larger (80B parameters), on several VQA and image-captioning tasks, and it also sustains performance on challenging language-only and vision-only tasks, which were not the main training objective.
PaLI (17B parameters) outperforms the state-of-the-art approaches (including SimVLM, CoCa, GIT2, Flamingo, BEiT3) on multiple vision-and-language tasks. In this plot we show the absolute score differences compared with the previous best model to highlight the relative improvements of PaLI. Comparison is on the official test splits when available. CIDEr score is used for evaluation of the image captioning tasks, whereas VQA tasks are evaluated by VQA Accuracy.<!–PaLI (17B parameters) outperforms the state-of-the-art approaches (including SimVLM, CoCa, GIT2, Flamingo, BEiT3) on multiple vision-and-language tasks. In this plot we show the absolute score differences compared with the previous best model to highlight the relative improvements of PaLI. Comparison is on the official test splits when available. CIDEr score is used for evaluation of the image captioning tasks, whereas VQA tasks are evaluated by VQA Accuracy.–>
{kind=link}
{kind=link}
Model Scaling Results
We examine how the image and language model components interact with each other with regards to model scaling and where the model yields the most gains. We conclude that scaling both components jointly results in the best performance, and specifically, scaling the visual component, which requires relatively few parameters, is most essential. Scaling is also critical for better performance across multilingual tasks.
Scaling both the language and the visual components of the PaLI model contribute to improved performance. The plot shows the score differences compared to the PaLI-3B model: CIDEr score is used for evaluation of the image captioning tasks, whereas VQA tasks are evaluated by VQA Accuracy.Multilingual captioning greatly benefits from scaling the PaLI models. We evaluate PaLI on a 35-language benchmark Crossmodal-3600. Here we present the average score over all 35 languages and the individual score for seven diverse languages.
{kind=link}
{kind=link}
Model Introspection: Model Fairness, Biases, and Other Potential Issues
To avoid creating or reinforcing unfair bias within large language and image models, important first steps are to (1) be transparent about the data that were used and how the model used those data, and (2) test for model fairness and conduct responsible data analyses. To address (1), our paper includes a data card and model card. To address (2), the paper includes results of demographic analyses of the dataset. We consider this a first step and know that it will be important to continue to measure and mitigate potential biases as we apply our model to new tasks, in alignment with our AI Principles.
Conclusion
We presented PaLI, a scalable multi-modal and multilingual model designed for solving a variety of vision-language tasks. We demonstrate improved performance across visual-, language- and vision-language tasks. Our work illustrates the importance of scale in both the visual and language parts of the model and the interplay between the two. We see that accomplishing vision and language tasks, especially in multiple languages, actually requires large scale models and data, and will potentially benefit from further scaling. We hope this work inspires further research in multi-modal and multilingual models.
Acknowledgements
We thank all the authors who conducted this research Soravit (Beer) Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Nan Ding, Keran Rong, Hassan Akbari,Gaurav Mishra, Linting Xue, Ashish Thapliyal, James Bradbury, Weicheng Kuo, Mojtaba Seyedhosseini, Chao Jia, Burcu Karagol Ayan, Carlos Riquelme, Andreas Steiner, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, Radu Soricut. We also thank Claire Cui, Slav Petrov, Tania Bedrax-Weiss, Joelle Barral, Tom Duerig, Paul Natsev, Fernando Pereira, Jeff Dean, Jeremiah Harmsen, Zoubin Ghahramani, Erica Moreira, Victor Gomes, Sarah Laszlo, Kathy Meier-Hellstern, Susanna Ricco, Rich Lee, Austin Tarango, Emily Denton, Bo Pang, Wei Li, Jihyung Kil, Tomer Levinboim, Julien Amelot, Zhenhai Zhu, Xiangning Chen, Liang Chen, Filip Pavetic, Daniel Keysers, Matthias Minderer, Josip Djolonga, Ibrahim Alabdulmohsin, Mostafa Dehghani, Yi Tay, Elizabeth Adkison, James Cockerille, Eric Ni, Anna Davies, and Maysam Moussalem for their suggestions, improvements and support. We thank Tom Small for providing visualizations for the blogpost.