
A long-standing problem in the intersection of computer vision and computer graphics, view synthesis is the task of creating new views of a scene from multiple pictures of that scene. This has received increased attention [1, 2, 3] since the introduction of neural radiance fields (NeRF). The problem is challenging because to accurately synthesize new views of a scene, a model needs to capture many types of information — its detailed 3D structure, materials, and illumination — from a small set of reference images.
In this post, we present recently published deep learning models for view synthesis. In “Light Field Neural Rendering” (LFNR), presented at CVPR 2022, we address the challenge of accurately reproducing view-dependent effects by using transformers that learn to combine reference pixel colors. Then in “Generalizable Patch-Based Neural Rendering” (GPNR), to be presented at ECCV 2022, we address the challenge of generalizing to unseen scenes by using a sequence of transformers with canonicalized positional encoding that can be trained on a set of scenes to synthesize views of new scenes. These models have some unique features. They perform image-based rendering, combining colors and features from the reference images to render novel views. They are purely transformer-based, operating on sets of image patches, and they leverage a 4D light field representation for positional encoding, which helps to model view-dependent effects.
We train deep learning models that are able to produce new views of a scene given a few images of it. These models are particularly effective when handling view-dependent effects like the refractions and translucency on the test tubes. This animation is compressed; see the original-quality renderings here. Source: Lab scene from the NeX/Shiny dataset.
{kind=link}
{kind=link}
Overview
The input to the models consists of a set of reference images and their camera parameters (focal length, position, and orientation in space), along with the coordinates of the target ray whose color we want to determine. To produce a new image, we start from the camera parameters of the input images, obtain the coordinates of the target rays (each corresponding to a pixel), and query the model for each.
Instead of processing each reference image completely, we look only at the regions that are likely to influence the target pixel. These regions are determined via epipolar geometry, which maps each target pixel to a line on each reference frame. For robustness, we take small regions around a number of points on the epipolar line, resulting in the set of patches that will actually be processed by the model. The transformers then act on this set of patches to obtain the color of the target pixel.
Transformers are especially useful in this setting since their self-attention mechanism naturally takes sets as inputs, and the attention weights themselves can be used to combine reference view colors and features to predict the output pixel colors. These transformers follow the architecture introduced in ViT.
To predict the color of one pixel, the models take a set of patches extracted around the epipolar line of each reference view. Image source: LLFF dataset.
{kind=link}
Light Field Neural Rendering
In Light Field Neural Rendering (LFNR), we use a sequence of two transformers to map the set of patches to the target pixel color. The first transformer aggregates information along each epipolar line, and the second along each reference image. We can interpret the first transformer as finding potential correspondences of the target pixel on each reference frame, and the second as reasoning about occlusion and view-dependent effects, which are common challenges of image-based rendering.
LFNR uses a sequence of two transformers to map a set of patches extracted along epipolar lines to the target pixel color.
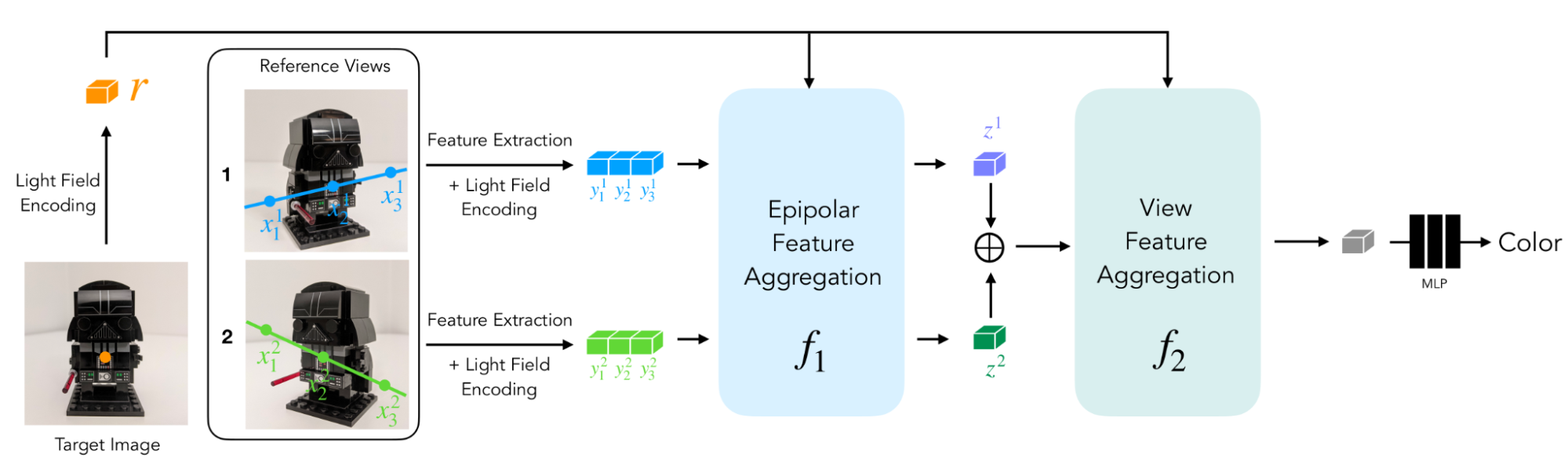{kind=link}
LFNR improved the state-of-the-art on the most popular view synthesis benchmarks (Blender and Real Forward-Facing scenes from NeRF and Shiny from NeX) with margins as large as 5dB peak signal-to-noise ratio (PSNR). This corresponds to a reduction of the pixel-wise error by a factor of 1.8x. We show qualitative results on challenging scenes from the Shiny dataset below:
LFNR reproduces challenging view-dependent effects like the rainbow and reflections on the CD, reflections, refractions and translucency on the bottles. This animation is compressed; see the original quality renderings here. Source: CD scene from the NeX/Shiny dataset.Prior methods such as NeX and NeRF fail to reproduce view-dependent effects like the translucency and refractions in the test tubes on the Lab scene from the NeX/Shiny dataset. See also our video of this scene at the top of the post and the original quality outputs here.
{kind=link}
{kind=link}
Generalizing to New Scenes
One limitation of LFNR is that the first transformer collapses the information along each epipolar line independently for each reference image. This means that it decides which information to preserve based only on the output ray coordinates and patches from each reference image, which works well when training on a single scene (as most neural rendering methods do), but it does not generalize across scenes. Generalizable methods are important because they can be applied to new scenes without needing to retrain.
We overcome this limitation of LFNR in Generalizable Patch-Based Neural Rendering (GPNR). We add a transformer that runs before the other two and exchanges information between points at the same depth over all reference images. For example, this first transformer looks at the columns of the patches from the park bench shown above and can use cues like the flower that appears at corresponding depths in two views, which indicates a potential match. Another key idea of this work is to canonicalize the positional encoding based on the target ray, because to generalize across scenes, it is necessary to represent quantities in relative and not absolute frames of reference. The animation below shows an overview of the model.
GPNR consists of a sequence of three transformers that map a set of patches extracted along epipolar lines to a pixel color. Image patches are mapped via the linear projection layer to initial features (shown as blue and green boxes). Then those features are successively refined and aggregated by the model, resulting in the final feature/color represented by the gray rectangle. Park bench image source: LLFF dataset.
{kind=link}
To evaluate the generalization performance, we train GPNR on a set of scenes and test it on new scenes. GPNR improved the state-of-the-art on several benchmarks (following IBRNet and MVSNeRF protocols) by 0.5–1.0 dB on average. On the IBRNet benchmark, GPNR outperforms the baselines while using only 11% of the training scenes. The results below show new views of unseen scenes rendered with no fine-tuning.
GPNR-generated views of held-out scenes, without any fine tuning. This animation is compressed; see the original quality renderings here. Source: IBRNet collected dataset. Details of GPNR-generated views on held-out scenes from NeX/Shiny (left) and LLFF (right), without any fine tuning. GPNR reproduces more accurately the details on the leaf and the refractions through the lens when compared against IBRNet.
{kind=link}
{kind=link}
Future Work
One limitation of most neural rendering methods, including ours, is that they require camera poses for each input image. Poses are not easy to obtain and typically come from offline optimization methods that can be slow, limiting possible applications, such as those on mobile devices. Research on jointly learning view synthesis and input poses is a promising future direction. Another limitation of our models is that they are computationally expensive to train. There is an active line of research on faster transformers which might help improve our models’ efficiency. For the papers, more results, and open-source code, you can check out the projects pages for “Light Field Neural Rendering” and “Generalizable Patch-Based Neural Rendering“.
Potential Misuse
In our research, we aim to accurately reproduce an existing scene using images from that scene, so there is little room to generate fake or non-existing scenes. Our models assume static scenes, so synthesizing moving objects, such as people, will not work.
Acknowledgments
All the hard work was done by our amazing intern – Mohammed Suhail – a PhD student at UBC, in collaboration with Carlos Esteves and Ameesh Makadia from Google Research, and Leonid Sigal from UBC. We are thankful to Corinna Cortes for supporting and encouraging this project.
Our work is inspired by NeRF, which sparked the recent interest in view synthesis, and IBRNet, which first considered generalization to new scenes. Our light ray positional encoding is inspired by the seminal paper Light Field Rendering and our use of transformers follow ViT.
Video results are from scenes from LLFF, Shiny, and IBRNet collected datasets.