
Open Images is a computer vision dataset covering ~9 million images with labels spanning thousands of object categories. Researchers around the world use Open Images to train and evaluate computer vision models. Since the initial release of Open Images in 2016, which included image-level labels covering 6k categories, we have provided multiple updates to enrich annotations and expand the potential use cases of the dataset. Through several releases, we have added image-level labels for over 20k categories on all images and bounding box annotations, visual relations, instance segmentations, and localized narratives (synchronized voice, mouse trace, and text caption) on a subset of 1.9M images.
Today, we are happy to announce the release of Open Images V7, which expands the Open Images dataset even further with a new annotation type called point-level labels and includes a new all-in-one visualization tool that allows a better exploration of the rich data available.
Point Labels
The main strategy used to collect the new point-level label annotations leveraged suggestions from a machine learning (ML) model and human verification. First, the ML model selected points of interest and asked a yes or no question, e.g., “is this point on a pumpkin?”. Then, human annotators spent an average of 1.1 seconds answering the yes or no questions. We aggregated the answers from different annotators over the same question and assigned a final “yes”, “no”, or “unsure” label to each annotated point.
Illustration of the annotations interface.
(Image by Lenore Edman, under CC BY 2.0 license)
{kind=link}
{kind=link}
For each annotated image, we provide a collection of points, each with a “yes” or “no” label for a given class. These points provide sparse information that can be used for the semantic segmentation task. We collected a total of 38.6M new point annotations (12.4M with “yes” labels) that cover 5.8 thousand classes and 1.4M images.
By focusing on point labels, we expanded the number of images annotated and categories covered. We also concentrated the efforts of our annotators on efficiently collecting useful information. Compared to our instance segmentation, the new points include 16x more classes and cover more images. The new points also cover 9x more classes than our box annotations. Compared to existing segmentation datasets, like PASCAL VOC, COCO, Cityscapes, LVIS, or ADE20K, our annotations cover more classes and more images than previous work. The new point label annotations are the first type of annotation in Open Images that provides localization information for both things (countable objects, like cars, cats, and catamarans), and stuff categories (uncountable objects like grass, granite, and gravel). Overall, the newly collected data is roughly equivalent to two years of human annotation effort.
Our initial experiments show that this type of sparse data is suitable for both training and evaluating segmentation models. Training a model directly on sparse data allows us to reach comparable quality to training on dense annotations. Similarly, we show that one can directly compute the traditional semantic segmentation intersection-over-union (IoU) metric over sparse data. The ranking across different methods is preserved, and the sparse IoU values are an accurate estimate of its dense version. See our paper for more details.
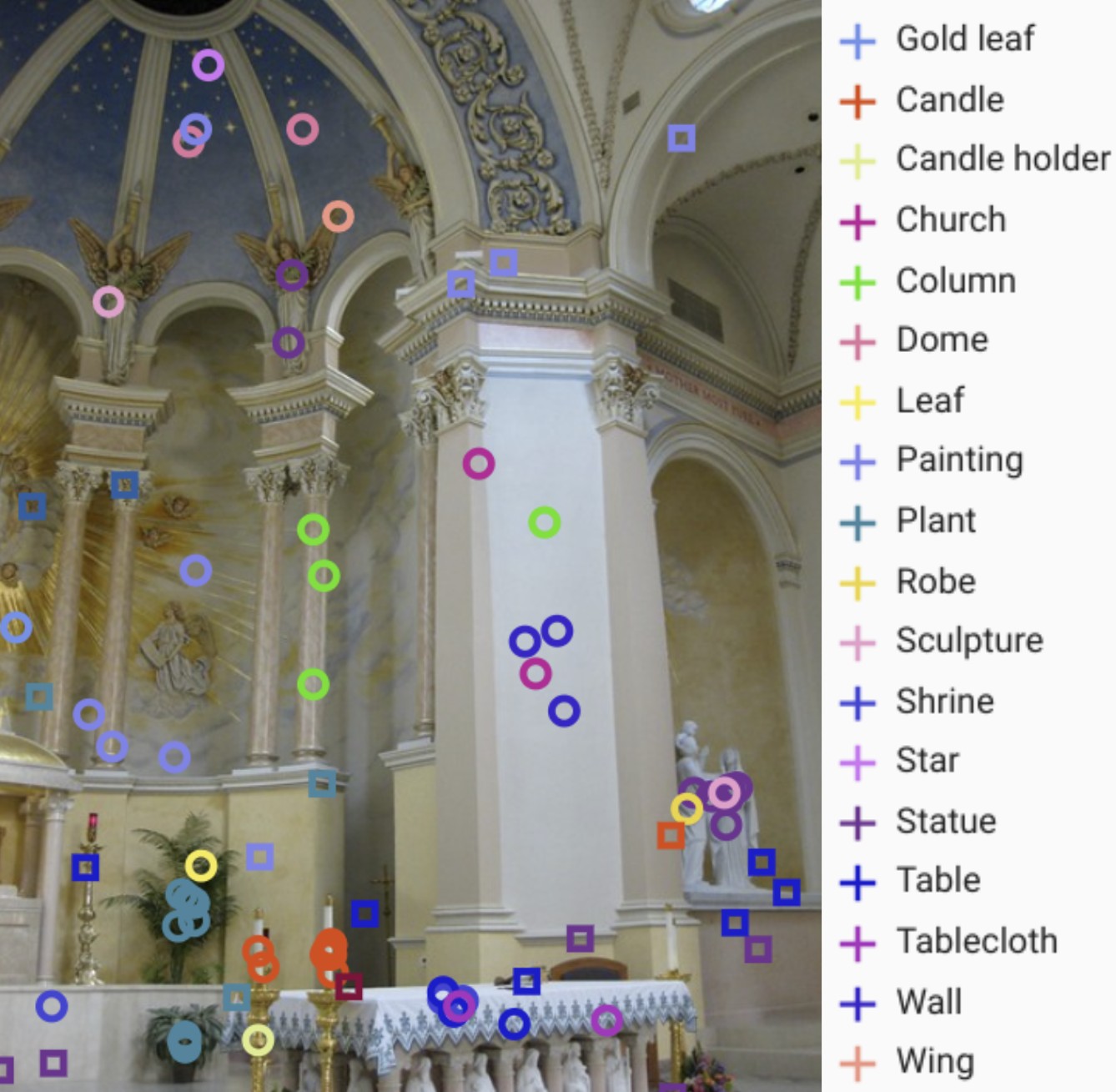
Below, we show four example images with their point-level labels, illustrating the rich and diverse information these annotations provide. Circles ⭘ are “yes” labels, and squares ☐ are “no” labels.
Four example images with point-level labels.
Images by Richie Diesterheft, John AM Nueva, Sarah Ackerman, and C Thomas, all under CC BY 2.0 license.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
New Visualizers
In addition to the new data release, we also expanded the available visualizations of the Open Images annotations. The Open Images website now includes dedicated visualizers to explore the localized narratives annotations, the new point-level annotations, and a new all-in-one view. This new all-in-one view is available for the subset of 1.9M densely annotated images and allows one to explore the rich annotations that Open Images has accumulated over seven releases. On average these images have annotations for 6.7 image-labels (classes), 8.3 boxes, 1.7 relations, 1.5 masks, 0.4 localized narratives and 34.8 point-labels per image.
Below, we show two example images with various annotations in the all-in-one visualizer. The figures show the image-level labels, bounding boxes, box relations, instance masks, localized narrative mouse trace and caption, and point-level labels. The + classes have positive annotations (of any kind), while – classes have only negative annotations (image-level or point-level).
Two example images with various annotations in the all-in-one visualizer.
Images by Jason Paris, and Rubén Vique, all under CC BY 2.0 license.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Conclusion
We hope that this new data release will enable computer vision research to cover ever more diverse and challenging scenarios. As the quality of automated semantic segmentation models improves over common classes, we want to move towards the long tail of visual concepts, and sparse point annotations are a step in that direction. More and more works are exploring how to use such sparse annotations (e.g., as supervision for instance segmentation or semantic segmentation), and Open Images V7 contributes to this research direction. We are looking forward to seeing what you will build next.
Acknowledgements
Thanks to Vittorio Ferrari, Jordi Pont-Tuset, Alina Kuznetsova, Ashlesha Sadras, and the annotators team for their support creating this new data release.