
In 2019 we launched Recorder, an audio recording app for Pixel phones that helps users create, manage, and edit audio recordings. It leverages recent developments in on-device machine learning to transcribe speech, recognize audio events, suggest tags for titles, and help users navigate transcripts.
Nonetheless, some Recorder users found it difficult to navigate long recordings that have multiple speakers because it’s not clear who said what. During the Made By Google event this year, we announced the “speaker labels” feature for the Recorder app. This opt-in feature annotates a recording transcript with unique and anonymous labels for each speaker (e.g., “Speaker 1”, “Speaker 2”, etc.) in real time during the recording. It significantly improves the readability and usability of the recording transcripts. This feature is powered by Google’s new speaker diarization system named Turn-to-Diarize, which was first presented at ICASSP 2022.
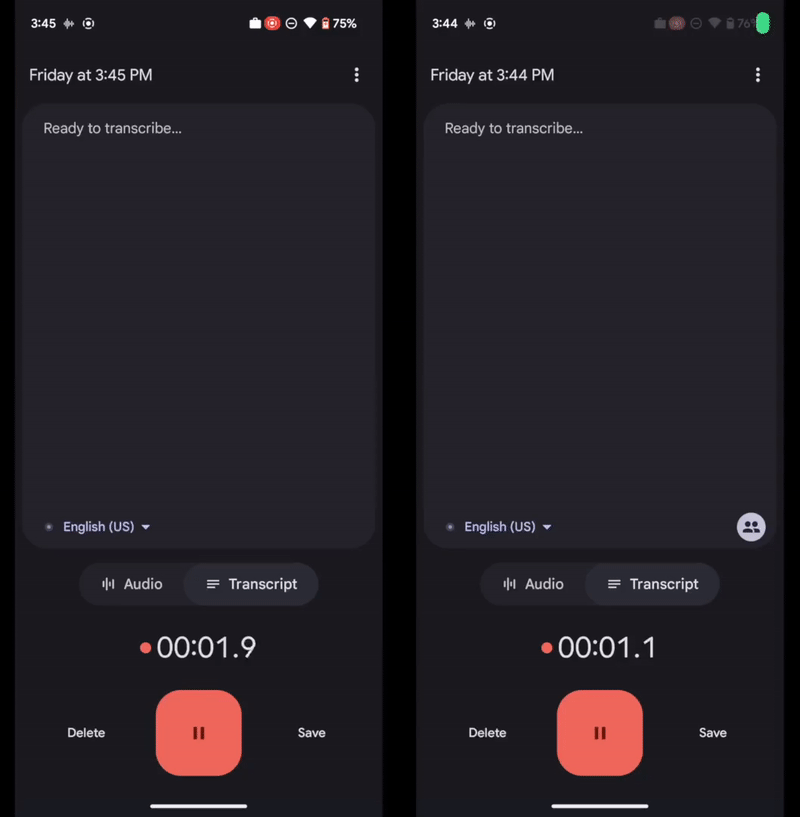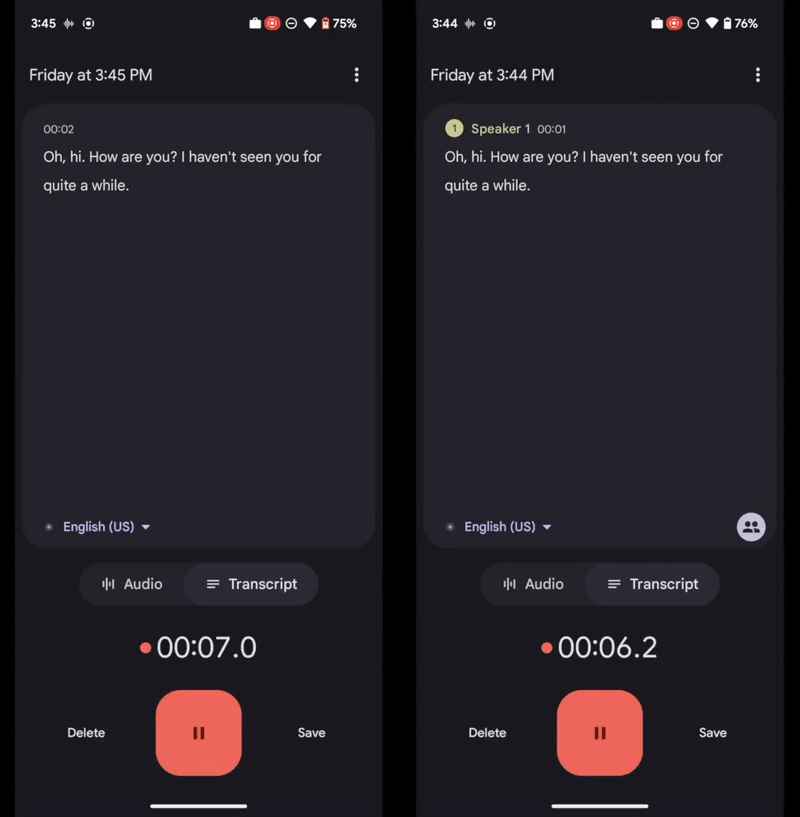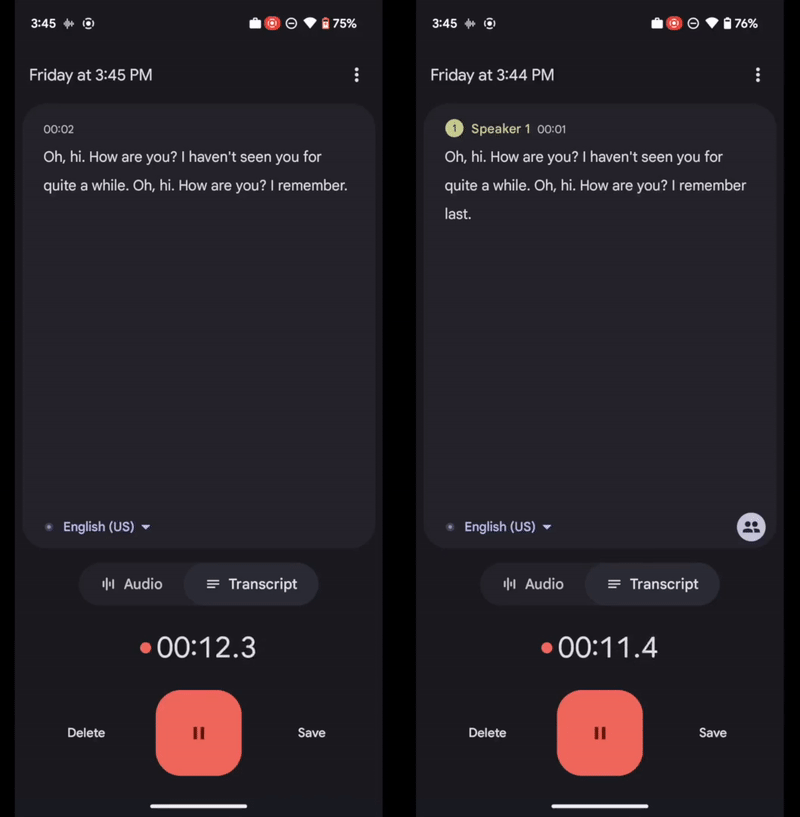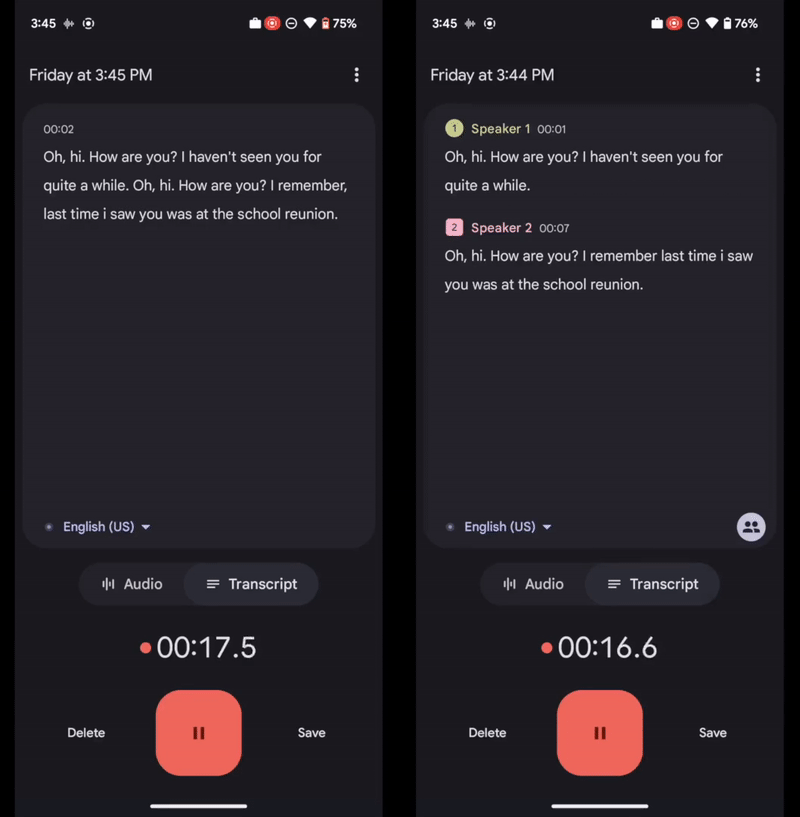
Left: Recorder transcript without speaker labels. Right: Recorder transcript with speaker labels.
{kind=link}
System Architecture
Our speaker diarization system leverages several highly optimized machine learning models and algorithms to allow diarizing hours of audio in a real-time streaming fashion with limited computational resources on mobile devices. The system mainly consists of three components: a speaker turn detection model that detects a change of speaker in the input speech, a speaker encoder model that extracts voice characteristics from each speaker turn, and a multi-stage clustering algorithm that annotates speaker labels to each speaker turn in a highly efficient way. All components run fully on the device.
Architecture of the Turn-to-Diarize system.
{kind=link}
Detecting Speaker Turns
The first component of our system is a speaker turn detection model based on a Transformer Transducer (T-T), which converts the acoustic features into text transcripts augmented with a special token <st> representing a speaker turn. Unlike preceding customized systems that use role-specific tokens (e.g., <doctor> and <patient>) for conversations, this model is more generic and can be trained on and deployed to various application domains.
In most applications, the output of a diarization system is not directly shown to users, but combined with a separate automatic speech recognition (ASR) system that is trained to have smaller word errors. Therefore, for the diarization system, we are relatively more tolerant to word token errors than errors of the <st> token. Based on this intuition, we propose a new token-level loss function that allows us to train a small speaker turn detection model with high accuracy on predicted <st> tokens. Combined with edit-based minimum Bayes risk (EMBR) training, this new loss function significantly improved the interval-based F1 score on seven evaluation datasets.
Extracting Voice Characteristics
Once the audio recording has been segmented into homogeneous speaker turns, we use a speaker encoder model to extract an embedding vector (i.e., d-vector) to represent the voice characteristics of each speaker turn. This approach has several advantages over prior work that extracts embedding vectors from small fixed-length segments. First, it avoids extracting an embedding from a segment containing speech from multiple speakers. At the same time, each embedding covers a relatively large time range that contains sufficient signals from the speaker. It also reduces the total number of embeddings to be clustered, thus making the clustering step less expensive. These embeddings are processed entirely on-device until speaker labeling of the transcript is completed, and then deleted.
Multi-Stage Clustering
After the audio recording is represented by a sequence of embedding vectors, the last step is to cluster these embedding vectors, and assign a speaker label to each. However, since audio recordings from the Recorder app can be as short as a few seconds, or as long as up to 18 hours, it is critical for the clustering algorithm to handle sequences of drastically different lengths.
For this we propose a multi-stage clustering strategy to leverage the benefits of different clustering algorithms. First, we use the speaker turn detection outputs to determine whether there are at least two different speakers in the recording. For short sequences, we use agglomerative hierarchical clustering (AHC) as the fallback algorithm. For medium-length sequences, we use spectral clustering as our main algorithm, and use the eigen-gap criterion for accurate speaker count estimation. For long sequences, we reduce computational cost by using AHC to pre-cluster the sequence before feeding it to the main algorithm. During the streaming, we keep a dynamic cache of previous AHC cluster centroids that can be reused for future clustering calls. This mechanism allows us to enforce an upper bound on the entire system with constant time and space complexity.
This multi-stage clustering strategy is a critical optimization for on-device applications where the budget for CPU, memory, and battery is very small, and allows the system to run in a low power mode even after diarizing hours of audio. As a tradeoff between quality and efficiency, the upper bound of the computational cost can be flexibly configured for devices with different computational resources.
Diagram of the multi-stage clustering strategy.
{kind=link}
Correction and Customization
In our real-time streaming speaker diarization system, as the model consumes more audio input, it accumulates confidence on predicted speaker labels, and may occasionally make corrections to previously predicted low-confidence speaker labels. The Recorder app automatically updates the speaker labels on the screen during recording to reflect the latest and most accurate predictions.
At the same time, the Recorder app’s UI allows the user to rename the anonymous speaker labels (e.g., “Speaker 2”) to customized labels (e.g., “car dealer”) for better readability and easier memorization for the user within each recording.
Recorder allows the user to rename the speaker labels for better readability.
{kind=link}
Future Work
Currently, our diarization system mostly runs on the CPU block of Google Tensor, Google’s custom-built chip that powers more recent Pixel phones. We are working on delegating more computations to the TPU block, which will further reduce the overall power consumption of the diarization system. Another future work direction is to leverage multilingual capabilities of speaker encoder and speech recognition models to expand this feature to more languages.
Acknowledgments
The work described in this post represents joint efforts from multiple teams within Google. Contributors include Quan Wang, Yiling Huang, Evan Clark, Qi Cao, Han Lu, Guanlong Zhao, Wei Xia, Hasim Sak, Alvin Zhou, Jason Pelecanos, Luiza Timariu, Allen Su, Fan Zhang, Hugh Love, Kristi Bradford, Vincent Peng, Raff Tsai, Richard Chou, Yitong Lin, Ann Lu, Kelly Tsai, Hannah Bowman, Tracy Wu, Taral Joglekar, Dharmesh Mokani, Ajay Dudani, Ignacio Lopez Moreno, Diego Melendo Casado, Nino Tasca, Alex Gruenstein.