
Great machine learning (ML) research requires great systems. With the increasing sophistication of the algorithms and hardware in use today and with the scale at which they run, the complexity of the software necessary to carry out day-to-day tasks only increases. In this post, we provide an overview of the numerous advances made across Google this past year in systems for ML that enable us to support the serving and training of complex models while easing the complexity of implementation for end users. This blog post also highlights our research on leveraging ML itself to help improve and design the next generations of system stacks.
Distributed systems for ML
This year, we’ve made significant strides in improving our systems to better support large-scale computation in ML and scientific computing in general. The Google TPU hardware has been designed with scaling in mind since its inception, and each year we strive to push the boundaries even further. This year, we designed state-of-the-art serving techniques for large models, improved automatic partitioning of tensor programs and reworked the APIs of our libraries to make sure all of those developments are accessible to a wide audience of users.
One of our biggest efficiency improvements this year is the CollectiveEinsum strategy for evaluating the large scale matrix multiplication operations that are at the heart of neural networks. Unlike previously popular SPMD partitioning strategies that separate communication from device-local computation, this approach uses the fast TPU ICI links to overlap them, leading to up to 1.38x performance improvements. This algorithm was also a key component of our work on efficiently scaling Transformer inference, which presents a wide variety of strategies that trade off between latency and hardware utilization, reaching state-of-the-art model FLOPs utilization (MFU) of 76% in throughput-optimized configurations.
An illustration of AllGather-Einsum with 2-way intra-layer model parallelism, proposed in CollectiveEinsum strategy. Top: Illustration of non-overlapped execution. Bottom: Illustration of the CollectiveEinsum technique.
{kind=link}
We have also integrated SPMD-style partitioning as a first class concept into both TensorFlow, with the DTensor extension, and JAX, with the redesigned array type. In both libraries, tensors that seem complete to the programmer can be transparently sharded over a number of devices just by attaching declarative layout annotations. In fact, both approaches are compatible with existing code written for single-device computations that can now scale into a multi-device program, usually without any code modifications!
Integrating SPMD partitioning into the core of our ML frameworks means that being able to infer and optimize the way array programs are mapped onto a larger set of devices is critical for performance. In the past, this motivated the development of GSPMD, an important milestone in this area. However, GSPMD relies heavily on heuristics, and it still sometimes requires non-trivial decisions to be made manually, which often results in suboptimal performance. To make partitioning inference fully automatic, we collaborated with external colleagues to develop Alpa, a fully automated system that explores strategies for both operator-level (model) parallelism and pipeline parallelism between larger sub-computations. It successfully matches hand-tuned performance on popular models such as Transformers, but is also capable of successfully scaling up other models, such as convolutional networks and mixture-of-experts models that often cause existing automated methods to struggle.
Alpa overview. The inter-operator identifies the best way to assign a subgraph to a submesh. The intra-operator pass finds the best intra-operator parallelism plan for each pipeline stage. Finally, the runtime orchestration generates a static plan that orders the computation and communication.
{kind=link}
In a similar vein, the recently published Pathways system adds an additional layer of virtualization on top of the usual TPU runtime — accelerators are managed by long-lived processes instead of being allocated directly to users. A single end user can then connect to an arbitrary number of Pathways-controlled devices and write their program as if all the devices were attached directly to their process, even though in reality they may even span multiple data centers. Thanks to Pathways: (1) job startup time can be reduced, (2) it is easier to achieve fault tolerance, and (3) multitenancy becomes a viable option, enabling multiple jobs to be executed simultaneously for even more efficient hardware utilization. The ease with which Pathways enables computation spanning multiple TPU pods is crucial, as it lets us avoid future scaling bottlenecks.
Pathways overview. Top Left: Distributed computation expressed as a Directed Acyclic Graph. Top Right: The resource manager allocates virtual slices of accelerator meshes for each compiled function (e.g., A, B, and C). Bottom: Centralized schedulers for gang-schedule computations that are then dispatched by per-shard executors. (See paper for details.)
{kind=link}
Another notable release is TensorStore, a new library for multi-dimensional array storage. TensorStore is particularly useful for training large language models (LLMs) with multi-controller runtimes, where every process only manages a subset of all parameters, all of which must be collated into a consistent checkpoint. TensorStore provides database-grade guarantees (ACID) for efficient and concurrent multi-dimensional array serialization into many storage backends (e.g., Google Cloud Storage, various filesystems, HTTP servers) and has been successfully used for compute-intensive workloads such as PaLM and reconstructions of the human cortex and fruit fly brain.
A fly brain reconstruction for which the underlying data can be easily accessed and manipulated using TensorStore.
{kind=link}
Programming languages for ML
The robustness and correctness of our technical infrastructure are vital for ML efforts, which is why we remain committed to ensuring that it is built on a sound technical and theoretical basis, backed by cutting-edge research in programming languages and compiler construction.
We continued investing in the open-source MLIR compiler infrastructure, building a more controllable, composable and modular compiler stack. In addition, much progress has been made in code generation for sparse linear algebra and it is now possible to generate both dense and sparse code from almost identical MLIR programs. Finally, we also continued the development of the IREE compiler, preparing it for use on both powerful computers located in data centers and mobile devices such as smartphones.
On the more theoretical side we explored ways to formalize and verify the code-generation techniques we use. We also published a novel approach used to implement and formalize automatic differentiation (AD) systems, which are central to ML libraries. We decomposed the reverse-mode AD algorithm into three independent program transformations, which are significantly simpler and easier to verify, highlighting the unique features of JAX’s implementation.
Leveraging programming language techniques, such as abstract interpretation and program synthesis, we successfully reduced the number of resources required to perform a neural architecture search (NAS). This effort, 𝛼NAS, led to the discovery of more efficient models without degradation in accuracy.
In the past year, we published a number of new open-source libraries in the JAX ecosystem, Rax and T5X being just two examples. With the continued effort around jax2tf, JAX models can now be deployed on mobile devices using TensorFlow Lite and on the web using TensorFlow.js.
Hardware accelerators & ML
Hardware design for ML
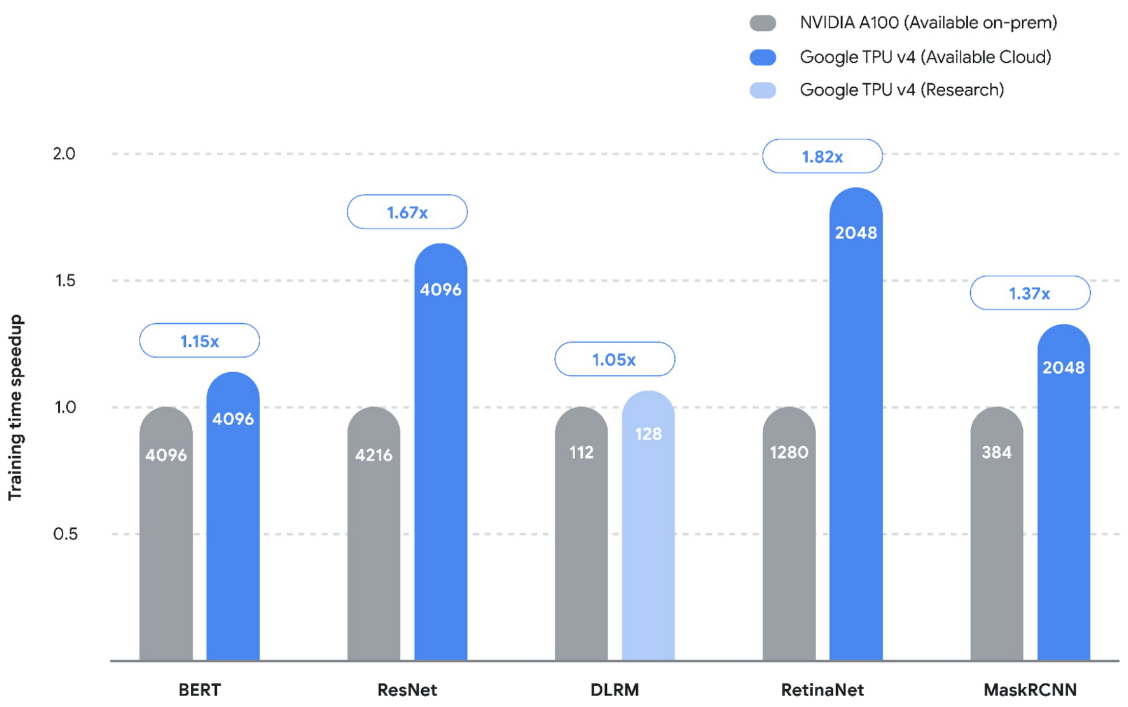
The use of customized hardware, such as TPUs and GPUs, has shown tremendous benefits in terms of both performance gain and energy efficiency (hence reducing the carbon footprint). In a recent MLPerf competition, we set new performance records on five benchmarks on TPUs v4, achieving speedups that are on average 1.42x higher than the next fastest submission. However, in order to keep up with recent advances, we are also developing customized hardware architectures for specific popular models.
TPUs demonstrated significant speedup in all five published benchmarks (MLPerf 2.0) over the fastest non-Google submission (NVIDIA on-premises). Taller bars are better. The numbers inside the bars represent the quantity of chips / accelerators used for each of the submissions.
{kind=link}
However, building a new hardware accelerator incurs high initial cost and requires significant development and deployment time. To make single-workload accelerators viable, the design cycle time has to be reduced. Full-stack Search Technique (FAST) addresses this problem by introducing a hardware accelerator search framework that simultaneously optimizes data path, scheduling, and important compiler decisions. FAST introduces an approximate template capable of describing diverse types of architectures and versatile memory hierarchy resulting in accelerators that improve single-workload performance per Thermal Design Power (known to highly correlate with performance per Total Cost of Ownership) by 3.7x compared to TPU v3. This shows that single-workload accelerators could be practical for moderate-sized datacenter deployments.
ML for hardware design
To automate the chip design process as much as possible, we continue to push the capabilities of ML at various stages of the hardware design, including high-level architectural exploration, verification, and placement and routing.
We recently open-sourced a distributed RL infrastructure called Circuit Training, along with a circuit environment described in our recent Nature paper. We used this infrastructure in production to produce macro placements for the latest generation of TPU chips. Tackling architectural exploration, PRIME introduces an ML-based approach for searching hardware design space that utilizes only existing data (e.g., from traditional accelerator design efforts) without any further hardware simulation. This approach alleviates the need to run time-consuming simulations, even when the set of target applications changes. PRIME improves performance over state-of-the-art simulation-driven methods by about 1.2x–1.5x while reducing the simulation time by 93%–99%. AutoApprox automatically generates approximate low-power deep learning accelerators without any accuracy loss by mapping each neural network layer to an appropriate approximation level.
PRIME uses logged accelerator data, consisting of both feasible and infeasible accelerators, to train a conservative model, which is used to design accelerators while meeting design constraints. PRIME designs accelerators with up to 1.5x smaller latency, while reducing the required hardware simulation time by up to 99%.
{kind=link}
Hardware-dependent model design
While NAS has shown tremendous capability in discovering state-of-the-art models in terms of accuracy and efficiency, it is still limited by lack of hardware knowledge. Platform-aware NAS addresses this gap by incorporating knowledge of the hardware architecture into the design of the NAS search space. The resulting EfficientNet-X model is 1.5x–2x faster than EfficientNet on TPU v3 and GPU v100, respectively, with similar accuracy. Both platform-aware NAS and EfficientNet-X have been deployed in production, demonstrating significant accuracy gains and up to ~40% efficiency improvement for various production vision models. NaaS goes even further by searching for neural network architectures and hardware architectures together. Using this approach on Edge TPUs, NaaS discovers vision models that are 2x more energy efficient with the same accuracy.
Overview of platform-aware NAS on TPUs/GPUs, highlighting the search space and search objectives.
{kind=link}
ML for navigating constrained search spaces
Apart from changing the hardware and the workload for better efficiency, we can also optimize the middle layer, including the partitioner, which maps the workload onto multiple devices, and the compiler, which translates the workload into a low-level presentation understood by the hardware. In previous years, we demonstrated how we can apply ML to find better device placement and compiler decisions. In the past year, we further explored this direction and found that many optimization search spaces are heavily constrained, where valid solutions are quite sparse.
To address this challenge, we developed several techniques to enable a learned model to effectively navigate a constrained search space. Telamalloc employs a combination of ML model plus heuristics to make a decision when multiple options are available, and leverages a constraint solver to infer further dependent decisions. Telamalloc speeds up the memory allocation pass in the Edge TPU compiler compared to a production Integer Linear Programming approach and enables important real-world models that could not otherwise be supported.
“A Transferable Approach for Partitioning Machine Learning Models on Multi-Chip-Modules” proposes a slightly different approach. It applies reinforcement learning (RL) to propose the decisions in a single step, and asks the constraint solver to adjust the proposed solution to be valid. For a BERT model on an Edge TPU-based multi-chip mesh, this approach discovers a better distribution of the model across devices using a much smaller time budget compared to non-learned search strategies.
ML for large-scale production systems
We also deployed ML to improve efficiency of various large-scale systems running in production. We recently released MLGO, the first industrial-grade general framework for integrating ML techniques systematically in the LLVM infrastructure. MLGO can replace heuristics in LLVM with an RL policy to make optimization decisions. When testing on a set of internal large-scale applications, we found that the trained policy can reduce binary size by 3%–7% when optimizing inlining decisions and can improve throughput by 0.3% ~1.5% when optimizing register allocation decisions. Within our production ML compiler, XLA, a learned cost model published a few years back, was recently deployed to guide the selection of optimal tile sizes of TPU kernels for top ML workloads, saving ~2% of the total TPU compute time in our data centers overall.We also recently replaced an existing heuristic in YouTube cache replacement algorithm with a new hybrid algorithm that combines a simple heuristic with a learned model, improving byte miss ratio at the peak by ~9%.
Illustration of MLGO during inlining. “#bbs”, “#users”, and “callsite height” are example caller-callee pair features.
{kind=link}
AI & sustainability
Given the global climate change crisis, there has been understandable concern about the environmental impact of ML. In a recent paper, we showed that by following best practices, ML practitioners can reduce carbon dioxide equivalent emissions (CO2e) from training by orders of magnitude. We call the practices the “4Ms”
Model. The first step is to select the most efficient ML model architecture. For example, Primer runs ~4x faster on the same hardware while achieving the same quality scores than the popular Transformer developed four years earlier. Machine. The second practice is to use the most energy efficient computer available. For example, when the Transformer model was first published in 2017, a popular GPU was the Nvidia P100. Using a recent processor optimized for ML training, such as TPU v4, improves performance per Watt by ~15x. Mechanization. Computers for training needed to be housed in a data center. Large cloud data centers are typically ~1.4x more energy-efficient than the typical smaller on-premise data center. Map. The biggest surprise in our investigation was the impact on the cleanliness of the energy supply by picking the best location. Moreover, in the cloud, location is the easiest of the four factors to change. The difference between a typical location and a well chosen location can be ~9x, even within the same country.
In this example, multiplying the 4Ms together yields a 4x × 15x × 1.4x × 9x or ~750x reduction in CO2e over four years by following the best practices over the training of the original Transformer model using GPUs of 2017.
We are continuing to explore this space and in 2023 we will be releasing a further study that demonstrates how to reduce the CO2e of current model training by up to 20x by carefully selecting the machine, mechanization and location of training.
Concluding thoughts
As the field of ML advances, we continue our investment in developing high-performance, energy-efficient, and easy-to-use systems and infrastructure to enable rapid exploration of new ideas. At the same time, we continue to explore the capability of ML to improve the performance of complex systems and automate labor-intensive tasks in system design.
Google Research, 2022 & beyond
This was the second blog post in the “Google Research, 2022 & Beyond” series. Other posts in this series are listed in the table below:
* Articles will be linked as they are released.