
Industrial applications of machine learning are commonly composed of various items that have differing data modalities or feature distributions. Heterogeneous graphs (HGs) offer a unified view of these multimodal data systems by defining multiple types of nodes (for each data type) and edges (for the relation between data items). For instance, e-commerce networks might have [user, product, review] nodes or video platforms might have [channel, user, video, comment] nodes. Heterogeneous graph neural networks (HGNNs) learn node embeddings summarizing each node’s relationships into a vector. However, in real world HGs, there is often a label imbalance issue between different node types. This means that label-scarce node types cannot exploit HGNNs, which hampers the broader applicability of HGNNs.
In “Zero-shot Transfer Learning within a Heterogeneous Graph via Knowledge Transfer Networks”, presented at NeurIPS 2022, we propose a model called a Knowledge Transfer Network (KTN), which transfers knowledge from label-abundant node types to zero-labeled node types using the rich relational information given in a HG. We describe how we pre-train a HGNN model without the need for fine-tuning. KTNs outperform state-of-the-art transfer learning baselines by up to 140% on zero-shot learning tasks, and can be used to improve many existing HGNN models on these tasks by 24% (or more).
KTNs transform labels from one type of information (squares) through a graph to another type (stars).
{kind=link}
What is a heterogeneous graph?
A HG is composed of multiple node and edge types. The figure below shows an e-commerce network presented as a HG. In e-commerce, “users” purchase “products” and write “reviews”. A HG presents this ecosystem using three node types [user, product, review] and three edge types [user-buy-product, user-write-review, review-on-product]. Individual products, users, and reviews are then presented as nodes and their relationships as edges in the HG with the corresponding node and edge types.
E-commerce heterogeneous graph.
{kind=link}
In addition to all connectivity information, HGs are commonly given with input node attributes that summarize each node’s information. Input node attributes could have different modalities across different node types. For instance, images of products could be given as input node attributes for the product nodes, while text can be given as input attributes to review nodes. Node labels (e.g., the category of each product or the category that most interests each user) are what we want to predict on each node.
HGNNs and label scarcity issues
HGNNs compute node embeddings that summarize each node’s local structures (including the node and its neighbor’s information). These node embeddings are utilized by a classifier to predict each node’s label. To train a HGNN model and a classifier to predict labels for a specific node type, we require a good amount of labels for the type.
A common issue in industrial applications of deep learning is label scarcity, and with their diverse node types, HGNNs are even more likely to face this challenge. For instance, publicly available content node types (e.g., product nodes) are abundantly labeled, whereas labels for user or account nodes may not be available due to privacy restrictions. This means that in most standard training settings, HGNN models can only learn to make good inferences for a few label-abundant node types and can usually not make any inferences for any remaining node types (given the absence of any labels for them).
Transfer learning on heterogeneous graphs
Zero-shot transfer learning is a technique used to improve the performance of a model on a target domain with no labels by using the knowledge learned by the model from another related source domain with adequately labeled data. To apply transfer learning to solve this label scarcity issue for certain node types in HGs, the target domain would be the zero-labeled node types. Then what would be the source domain? Previous work commonly sets the source domain as the same type of nodes located in a different HG, assuming those nodes are abundantly labeled. This graph-to-graph transfer learning approach pre-trains a HGNN model on the external HG and then runs the model on the original (label-scarce) HG.
However, these approaches are not applicable in many real-world scenarios for three reasons. First, any external HG that could be used in a graph-to-graph transfer learning setting would almost surely be proprietary, thus, likely unavailable. Second, even if practitioners could obtain access to an external HG, it is unlikely the distribution of that source HG would match their target HG well enough to apply transfer learning. Finally, node types suffering from label scarcity are likely to suffer the same issue on other HGs (e.g., privacy issues on user nodes).
Our approach: Transfer learning between node types within a heterogeneous graph
Here, we shed light on a more practical source domain, other node types with abundant labels located on the same HG. Instead of using extra HGs, we transfer knowledge within a single HG (assumed to be fully owned by the practitioners) across different types of nodes. More specifically, we pre-train a HGNN model and a classifier on a label-abundant (source) node type, then reuse the models on the zero-labeled (target) node types located in the same HG without additional fine-tuning. The one requirement is that the source and target node types share the same label set (e.g., in the e-commerce HG, product nodes have a label set describing product categories, and user nodes share the same label set describing their favorite shopping categories).
Why is it challenging?
Unfortunately, we cannot directly reuse the pre-trained HGNN and classifier on the target node type. One crucial characteristic of HGNN architectures is that they are composed of modules specialized to each node type to fully learn the multiplicity of HGs. HGNNs use distinct sets of modules to compute embeddings for each node type. In the figure below, blue- and red-colored modules are used to compute node embeddings for the source and target node types, respectively.
HGNNs are composed of modules specialized to each node type and use distinct sets of modules to compute embeddings of different node types. More details can be found in the paper.
{kind=link}
While pre-training HGNNs on the source node type, source-specific modules in the HGNNs are well trained, however target-specific modules are under-trained as they have only a small amount of gradients flowing into them. This is shown below, where we see that the L2 norm of gradients for target node types (i.e., Mtt) are much lower than for source types (i.e., Mss). In this case a HGNN model outputs poor node embeddings for the target node type, which results in poor task performance.
In HGNNs, target type-specific modules receive zero or only a small amount of gradients during pre-training on the source node type, leading to poor performance on the target node type.
{kind=link}
{kind=link}
KTN: Trainable cross-type transfer learning for HGNNs
Our work focuses on transforming the (poor) target node embeddings computed by a pre-trained HGNN model to follow the distribution of the source node embeddings. Then the classifier, pre-trained on the source node type, can be reused for the target node type. How can we map the target node embeddings to the source domain? To answer this question, we investigate how HGNNs compute node embeddings to learn the relationship between source and target distributions.
HGNNs aggregate connected node embeddings to augment a target node’s embeddings in each layer. In other words, the node embeddings for both source and target node types are updated using the same input — the previous layer’s node embeddings of any connected node types. This means that they can be represented by each other. We prove this relationship theoretically and find there is a mapping matrix (defined by HGNN parameters) from the target domain to the source domain (more details in Theorem 1 in the paper). Based on this theorem, we introduce an auxiliary neural network, which we refer to as a Knowledge Transfer Network (KTN), that receives the target node embeddings and then transforms them by multiplying them with a (trainable) mapping matrix. We then define a regularizer that is minimized along with the performance loss in the pre-training phase to train the KTN. At test time, we map the target embeddings computed from the pre-trained HGNN to the source domain using the trained KTN for classification.
In HGNNs, the final node embeddings of both source and target types are computed from different mathematical functions (f(): source, g(): target) which use the same input — the previous layer’s node embeddings.
{kind=link}
Experimental results
To examine the effectiveness of KTNs, we ran 18 different zero-shot transfer learning tasks on two public heterogeneous graphs, Open Academic Graph and Pubmed. We compare KTN with eight state-of-the-art transfer learning methods (DAN, JAN, DANN, CDAN, CDAN-E, WDGRL, LP, EP). Shown below, KTN consistently outperforms all baselines on all tasks, beating transfer learning baselines by up to 140% (as measured by Normalized Discounted Cumulative Gain, a ranking metric).
Zero-shot transfer learning on Open Academic Graph (OAG-CS) and Pubmed datasets. The colors represent different categories of transfer learning baselines against which the results are compared. Yellow: Use statistical properties (e.g., mean, variance) of distributions. Green: Use adversarial models to transfer knowledge. Orange: Transfer knowledge directly via graph structure using label propagation.
{kind=link}
{kind=link}
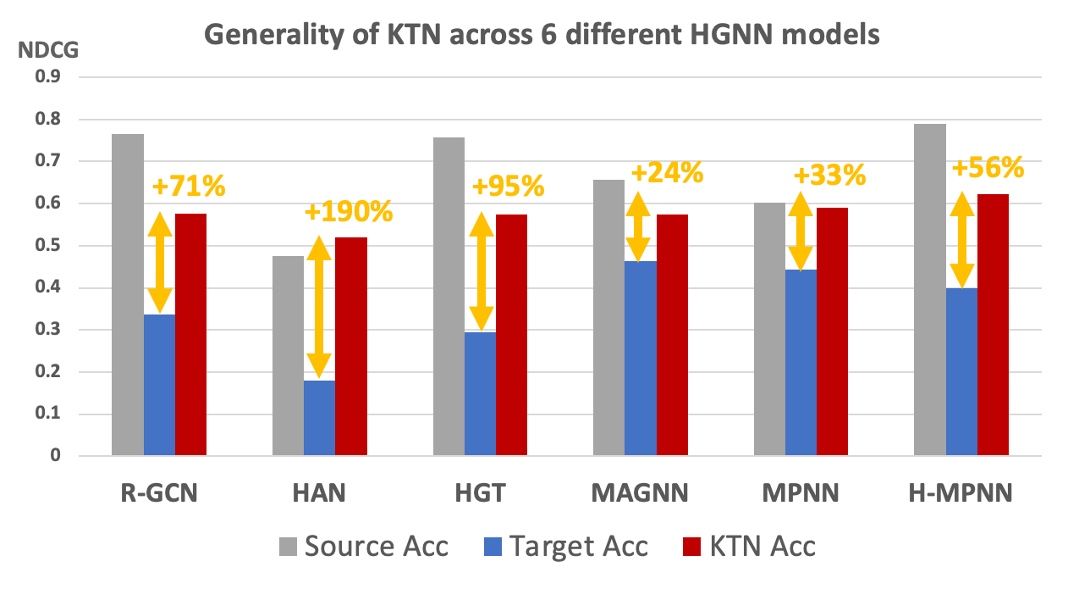
Most importantly, KTN can be applied to almost all HGNN models that have node and edge type-specific parameters and improve their zero-shot performance on target domains. As shown below, KTN improves accuracy on zero-labeled node types across six different HGNN models(R-GCN, HAN, HGT, MAGNN, MPNN, H-MPNN) by up to 190%.
KTN can be applied to six different HGNN models and improve their zero-shot performance on target domains.
{kind=link}
Takeaways
Various ecosystems in industry can be presented as heterogeneous graphs. HGNNs summarize heterogeneous graph information into effective representations. However, label scarcity issues on certain types of nodes prevent the wider application of HGNNs. In this post, we introduced KTN, the first cross-type transfer learning method designed for HGNNs. With KTN, we can fully exploit the richness of heterogeneous graphs via HGNNs regardless of label scarcity. See the paper for more details.
Acknowledgements
This paper is joint work with our co-authors John Palowitch (Google Research), Dustin Zelle (Google Research), Ziniu Hu (Intern, Google Research), and Russ Salakhutdinov (CMU). We thank Tom Small for creating the animated figure in this blog post.