
Detection is a fundamental vision task that aims to localize and recognize objects in an image. However, the data collection process of manually annotating bounding boxes or instance masks is tedious and costly, which limits the modern detection vocabulary size to roughly 1,000 object classes. This is orders of magnitude smaller than the vocabulary people use to describe the visual world and leaves out many categories. Recent vision and language models (VLMs), such as CLIP, have demonstrated improved open-vocabulary visual recognition capabilities through learning from Internet-scale image-text pairs. These VLMs are applied to zero-shot classification using frozen model weights without the need for fine-tuning, which stands in stark contrast to the existing paradigms used for retraining or fine-tuning VLMs for open-vocabulary detection tasks.
Intuitively, to align the image content with the text description during training, VLMs may learn region-sensitive and discriminative features that are transferable to object detection. Surprisingly, features of a frozen VLM contain rich information that are both region sensitive for describing object shapes (second column below) and discriminative for region classification (third column below). In fact, feature grouping can nicely delineate object boundaries without any supervision. This motivates us to explore the use of frozen VLMs for open-vocabulary object detection with the goal to expand detection beyond the limited set of annotated categories.
We explore the potential of frozen vision and language features for open-vocabulary detection. The K-Means feature grouping reveals rich semantic and region-sensitive information where object boundaries are nicely delineated (column 2). The same frozen features can classify groundtruth (GT) regions well without fine-tuning (column 3).
{kind=link}
In “F-VLM: Open-Vocabulary Object Detection upon Frozen Vision and Language Models”, presented at ICLR 2023, we introduce a simple and scalable open-vocabulary detection approach built upon frozen VLMs. F-VLM reduces the training complexity of an open-vocabulary detector to below that of a standard detector, obviating the need for knowledge distillation, detection-tailored pre-training, or weakly supervised learning. We demonstrate that by preserving the knowledge of pre-trained VLMs completely, F-VLM maintains a similar philosophy to ViTDet and decouples detector-specific learning from the more task-agnostic vision knowledge in the detector backbone. We are also releasing the F-VLM code along with a demo on our project page.
Learning upon frozen vision and language models
We desire to retain the knowledge of pretrained VLMs as much as possible with a view to minimize effort and cost needed to adapt them for open-vocabulary detection. We use a frozen VLM image encoder as the detector backbone and a text encoder for caching the detection text embeddings of offline dataset vocabulary. We take this VLM backbone and attach a detector head, which predicts object regions for localization and outputs detection scores that indicate the probability of a detected box being of a certain category. The detection scores are the cosine similarity of region features (a set of bounding boxes that the detector head outputs) and category text embeddings. The category text embeddings are obtained by feeding the category names through the text model of pretrained VLM (which has both image and text models)r.
The VLM image encoder consists of two parts: 1) a feature extractor and 2) a feature pooling layer. We adopt the feature extractor for detector head training, which is the only step we train (on standard detection data), to allow us to directly use frozen weights, inheriting rich semantic knowledge (e.g., long-tailed categories like martini, fedora hat, pennant) from the VLM backbone. The detection losses include box regression and classification losses.
At training time, F-VLM is simply a detector with the last classification layer replaced by base-category text embeddings.
{kind=link}
Region-level open-vocabulary recognition
The ability to perform open-vocabulary recognition at region level (i.e., bounding box level as opposed to image level) is integral to F-VLM. Since the backbone features are frozen, they do not overfit to the training categories (e.g., donut, zebra) and can be directly cropped for region-level classification. F-VLM performs this open-vocabulary classification only at test time. To obtain the VLM features for a region, we apply the feature pooling layer on the cropped backbone output features. Because the pooling layer requires fixed-size inputs, e.g., 7×7 for ResNet50 (R50) CLIP backbone, we crop and resize the region features with the ROI-Align layer (shown below). Unlike existing open-vocabulary detection approaches, we do not crop and resize the RGB image regions and cache their embeddings in a separate offline process, but train the detector head in one stage. This is simpler and makes more efficient use of disk storage space.. In addition, we do not crop VLM region features during training because the backbone features are frozen.
Despite never being trained on regions, the cropped region features maintain good open-vocabulary recognition capability. However, we observe the cropped region features are not sensitive enough to the localization quality of the regions, i.e., a loosely vs. tightly localized box both have similar features. This may be good for classification, but is problematic for detection because we need the detection scores to reflect localization quality as well. To remedy this, we apply the geometric mean to combine the VLM scores with the detection scores for each region and category. The VLM scores indicate the probability of a detection box being of a certain category according to the pretrained VLM. The detection scores indicate the class probability distribution of each box based on the similarity of region features and input text embeddings.
At test time, F-VLM uses the region proposals to crop out the top-level features of the VLM backbone and compute the VLM score per region. The trained detector head provides the detection boxes and masks, while the final detection scores are a combination of detection and VLM scores.
{kind=link}
Evaluation
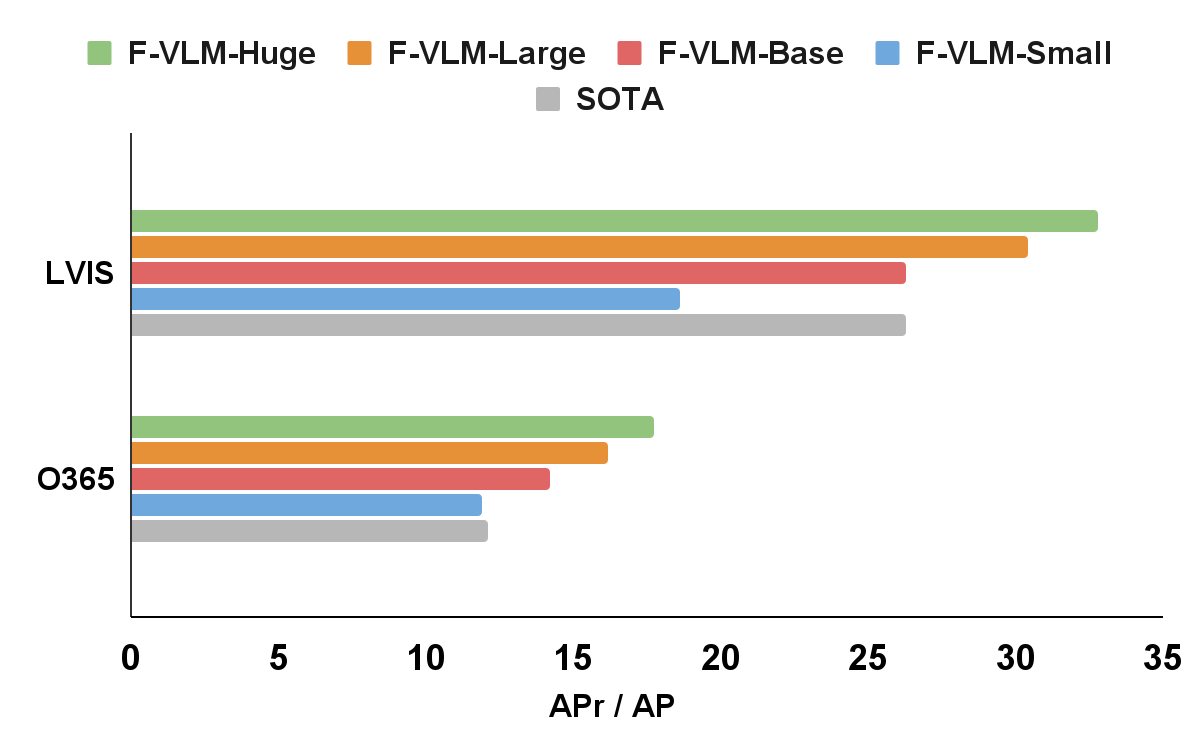
We apply F-VLM to the popular LVIS open-vocabulary detection benchmark. At the system-level, the best F-VLM achieves 32.8 average precision (AP) on rare categories (APr), which outperforms the state of the art by 6.5 mask APr and many other approaches based on knowledge distillation, pre-training, or joint training with weak supervision. F-VLM shows strong scaling property with frozen model capacity, while the number of trainable parameters is fixed. Moreover, F-VLM generalizes and scales well in the transfer detection tasks (e.g., Objects365 and Ego4D datasets) by simply replacing the vocabularies without fine-tuning the model. We test the LVIS-trained models on the popular Objects365 datasets and demonstrate that the model can work very well without training on in-domain detection data.
F-VLM outperforms the state of the art (SOTA) on LVIS open-vocabulary detection benchmark and transfer object detection. On the x-axis, we show the LVIS metric mask AP on rare categories (APr), and the Objects365 (O365) metric box AP on all categories. The sizes of the detector backbones are as follows: Small(R50), Base (R50x4), Large(R50x16), Huge(R50x64). The naming follows CLIP convention.
{kind=link}
We visualize F-VLM on open-vocabulary detection and transfer detection tasks (shown below). On LVIS and Objects365, F-VLM correctly detects both novel and common objects. A key benefit of open-vocabulary detection is to test on out-of-distribution data with categories given by users on the fly. See the F-VLM paper for more visualization on LVIS, Objects365 and Ego4D datasets.
F-VLM open-vocabulary and transfer detections. Top: Open-vocabulary detection on LVIS. We only show the novel categories for clarity. Bottom: Transfer to Objects365 dataset shows accurate detection of many categories. Novel categories detected: fedora, martini, pennant, football helmet (LVIS); slide (Objects365).
{kind=link}
Training efficiency
We show that F-VLM can achieve top performance with much less computational resources in the table below. Compared to the state-of-the-art approach, F-VLM can achieve better performance with 226x fewer resources and 57x faster wall clock time. Apart from training resource savings, F-VLM has potential for substantial memory savings at training time by running the backbone in inference mode. The F-VLM system runs almost as fast as a standard detector at inference time, because the only addition is a single attention pooling layer on the detected region features.
Method
APr
Training Epochs
Training Cost
(per-core-hour)
Training Cost Savings
26.3
460
8,000
1x
F-VLM
32.8
118
565
14x
F-VLM
31.0
14.7
71
113x
F-VLM
27.7
7.4
35
226x
We provide additional results using the shorter Detectron2 training recipes (12 and 36 epochs), and show similarly strong performance by using a frozen backbone. The default setting is marked in gray.
Backbone
#Epochs
Batch Size
APr
R50
12
16
18.1
R50
36
64
18.5
R50
✓
100
256
18.6
R50x64
12
16
31.9
R50x64
36
64
32.6
R50x64
✓
100
256
32.8
Conclusion
We present F-VLM – a simple open-vocabulary detection method which harnesses the power of frozen pre-trained large vision-language models to provide detection of novel objects. This is done without a need for knowledge distillation, detection-tailored pre-training, or weakly supervised learning. Our approach offers significant compute savings and obviates the need for image-level labels. F-VLM achieves the new state-of-the-art in open-vocabulary detection on the LVIS benchmark at system level, and shows very competitive transfer detection on other datasets. We hope this study can both facilitate further research in novel-object detection and help the community explore frozen VLMs for a wider range of vision tasks.
Acknowledgements
This work is conducted by Weicheng Kuo, Yin Cui, Xiuye Gu, AJ Piergiovanni, and Anelia Angelova. We would like to thank our colleagues at Google Research for their advice and helpful discussions.