
Three years ago we wrote about our work on predicting a number of cardiovascular risk factors from fundus photos (i.e., photos of the back of the eye)1 using deep learning. That such risk factors could be extracted from fundus photos was a novel discovery and thus a surprising outcome to clinicians and laypersons alike. Since then, we and other researchers have discovered additional novel biomarkers from fundus photos, such as markers for chronic kidney disease and diabetes, and hemoglobin levels to detect anemia.
A unifying goal of work like this is to develop new disease detection or monitoring approaches that are less invasive, more accurate, cheaper and more readily available. However, one restriction to potential broad population-level applicability of efforts to extract biomarkers from fundus photos is getting the fundus photos themselves, which requires specialized imaging equipment and a trained technician.
The eye can be imaged in multiple ways. A common approach for diabetic retinal disease screening is to examine the posterior segment using fundus photographs (left), which have been shown to contain signals of kidney and heart disease, as well as anemia. Another way is to take photographs of the front of the eye (external eye photos; right), which is typically used to track conditions affecting the eyelids, conjunctiva, cornea, and lens.
{kind=link}
In “Detection of signs of disease in external photographs of the eyes via deep learning”, in press at Nature Biomedical Engineering, we show that a deep learning model can extract potentially useful biomarkers from external eye photos (i.e., photos of the front of the eye). In particular, for diabetic patients, the model can predict the presence of diabetic retinal disease, elevated HbA1c (a biomarker of diabetic blood sugar control and outcomes), and elevated blood lipids (a biomarker of cardiovascular risk). External eye photos as an imaging modality are particularly interesting because their use may reduce the need for specialized equipment, opening the door to various avenues of improving the accessibility of health screening.
Developing the Model
To develop the model, we used de-identified data from over 145,000 patients from a teleretinal diabetic retinopathy screening program. We trained a convolutional neural network both on these images and on the corresponding ground truth for the variables we wanted the model to predict (i.e., whether the patient has diabetic retinal disease, elevated HbA1c, or elevated lipids) so that the neural network could learn from these examples. After training, the model is able to take external eye photos as input and then output predictions for whether the patient has diabetic retinal disease, or elevated sugars or lipids.
A schematic showing the model generating predictions for an external eye photo.
{kind=link}
We measured model performance using the area under the receiver operator characteristic curve (AUC), which quantifies how frequently the model assigns higher scores to patients who are truly positive than patients who are truly negative (i.e., a perfect model scores 100%, compared to 50% for random guesses). The model detected various forms of diabetic retinal disease with AUCs of 71-82%, AUCs of 67-70% for elevated HbA1c, and AUCs of 57-68% for elevated lipids. These results indicate that, though imperfect, external eye photos can help detect and quantify various parameters of systemic health.
Much like the CDC’s pre-diabetes screening questionnaire, external eye photos may be able to help “pre-screen” people and identify those who may benefit from further confirmatory testing. If we sort all patients in our study based on their predicted risk and look at the top 5% of that list, 69% of those patients had HbA1c measurements ≥ 9 (indicating poor blood sugar control for patients with diabetes). For comparison, among patients who are at highest risk according to a risk score based on demographics and years with diabetes, only 55% had HbA1c ≥ 9, and among patients selected at random only 33% had HbA1c ≥ 9.
Assessing Potential Bias
We emphasize that this is promising, yet early, proof-of-concept research showcasing a novel discovery. That said, because we believe that it is important to evaluate potential biases in the data and model, we undertook a multi-pronged approach for bias assessment.
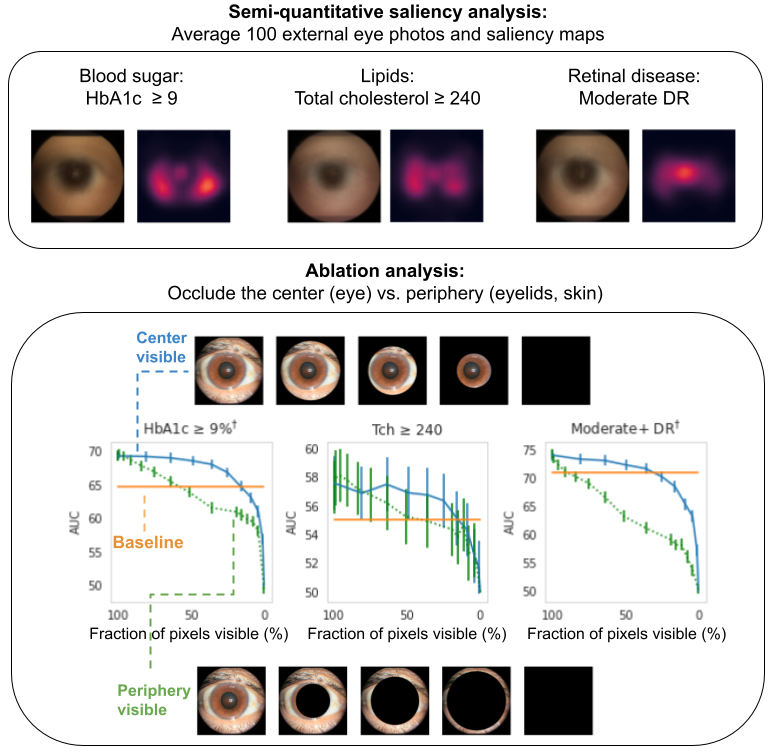
First, we conducted various explainability analyses aimed at discovering what parts of the image contribute most to the algorithm’s predictions (similar to our anemia work). Both saliency analyses (which examine which pixels most influenced the predictions) and ablation experiments (which examine the impact of removing various image regions) indicate that the algorithm is most influenced by the center of the image (the areas of the sclera, iris, and pupil of the eye, but not the eyelids). This is demonstrated below where one can see that the AUC declines much more quickly when image occlusion starts in the center (green lines) than when it starts in the periphery (blue lines).
Explainability analysis shows that (top) all predictions focused on different parts of the eye, and that (bottom) occluding the center of the image (corresponding to parts of the eyeball) has a much greater effect than occluding the periphery (corresponding to the surrounding structures, such as eyelids), as shown by the green line’s steeper decline. The “baseline” is a logistic regression model that takes self-reported age, sex, race and years with diabetes as input.
{kind=link}
Second, our development dataset spanned a diverse set of locations within the U.S., encompassing over 300,000 de-identified photos taken at 301 diabetic retinopathy screening sites. Our evaluation datasets comprised over 95,000 images from 198 sites in 18 US states, including datasets of predominantly Hispanic or Latino patients, a dataset of majority Black patients, and a dataset that included patients without diabetes. We conducted extensive subgroup analyses across groups of patients with different demographic and physical characteristics (such as age, sex, race and ethnicity, presence of cataract, pupil size, and even camera type), and controlled for these variables as covariates. The algorithm was more predictive than the baseline in all subgroups after accounting for these factors.
Conclusion
This exciting work demonstrates the feasibility of extracting useful health related signals from external eye photographs, and has potential implications for the large and rapidly growing population of patients with diabetes or other chronic diseases. There is a long way to go to achieve broad applicability, for example understanding what level of image quality is needed, generalizing to patients with and without known chronic diseases, and understanding generalization to images taken with different cameras and under a wider variety of conditions, like lighting and environment. In continued partnership with academic and nonacademic experts, including EyePACS and CGMH, we look forward to further developing and testing our algorithm on larger and more comprehensive datasets, and broadening the set of biomarkers recognized (e.g., for liver disease). Ultimately we are working towards making non-invasive health and wellness tools more accessible to everyone.
Acknowledgements
This work involved the efforts of a multidisciplinary team of software engineers, researchers, clinicians and cross functional contributors. Key contributors to this project include: Boris Babenko, Akinori Mitani, Ilana Traynis, Naho Kitade, Preeti Singh, April Y. Maa, Jorge Cuadros, Greg S. Corrado, Lily Peng, Dale R. Webster, Avinash Varadarajan, Naama Hammel, and Yun Liu. The authors would also like to acknowledge Huy Doan, Quang Duong, Roy Lee, and the Google Health team for software infrastructure support and data collection. We also thank Tiffany Guo, Mike McConnell, Michael Howell, and Sam Kavusi for their feedback on the manuscript. Last but not least, gratitude goes to the graders who labeled data for the pupil segmentation model, and a special thanks to Tom Small for the ideation and design that inspired the animation used in this blog post.
1The information presented here is research and does not reflect a product that is available for sale. Future availability cannot be guaranteed. ↩