
The task of determining the similarity between images is an open problem in computer vision and is crucial for evaluating the realism of machine-generated images. Though there are a number of straightforward methods of estimating image similarity (e.g., low-level metrics that measure pixel differences, such as FSIM and SSIM), in many cases, the measured similarity differences do not match the differences perceived by a person. However, more recent work has demonstrated that intermediate representations of neural network classifiers, such as AlexNet, VGG and SqueezeNet trained on ImageNet, exhibit perceptual similarity as an emergent property. That is, Euclidean distances between encoded representations of images by ImageNet-trained models correlate much better with a person’s judgment of differences between images than estimating perceptual similarity directly from image pixels.
Two sets of sample images from the BAPPS dataset. Trained networks agree more with human judgements as compared to low-level metrics (PSNR, SSIM, FSIM). Image source: Zhang et al. (2018).
{kind=link}
In “Do better ImageNet classifiers assess perceptual similarity better?” published in Transactions on Machine Learning Research, we contribute an extensive experimental study on the relationship between the accuracy of ImageNet classifiers and their emergent ability to capture perceptual similarity. To evaluate this emergent ability, we follow previous work in measuring the perceptual scores (PS), which is roughly the correlation between human preferences to that of a model for image similarity on the BAPPS dataset. While prior work studied the first generation of ImageNet classifiers, such as AlexNet, SqueezeNet and VGG, we significantly increase the scope of the analysis incorporating modern classifiers, such as ResNets and Vision Transformers (ViTs), across a wide range of hyper-parameters.
Relationship Between Accuracy and Perceptual Similarity
It is well established that features learned via training on ImageNet transfer well to a number of downstream tasks, making ImageNet pre-training a standard recipe. Further, better accuracy on ImageNet usually implies better performance on a diverse set of downstream tasks, such as robustness to common corruptions, out-of-distribution generalization and transfer learning on smaller classification datasets. Contrary to prevailing evidence that suggests models with high validation accuracies on ImageNet are likely to transfer better to other tasks, surprisingly, we find that representations from underfit ImageNet models with modest validation accuracies achieve the best perceptual scores.
Plot of perceptual scores (PS) on the 64 × 64 BAPPS Dataset (y-axis) against the ImageNet 64 × 64 validation accuracies (x-axis). Each blue dot represents an ImageNet classifier. Better ImageNet classifiers achieve better PS up to a certain point (dark blue), beyond which improving the accuracy lowers the PS. The best PS are attained by classifiers with moderate accuracy (20.0–40.0).<!–Plot of perceptual scores (PS) on the 64 × 64 BAPPS Dataset (y-axis) against the ImageNet 64 × 64 validation accuracies (x-axis). Each blue dot represents an ImageNet classifier. Better ImageNet classifiers achieve better PS up to a certain point (dark blue), beyond which improving the accuracy lowers the PS. The best PS are attained by classifiers with moderate accuracy (20.0–40.0).–>
{kind=link}
{kind=link}
We study the variation of perceptual scores as a function of neural network hyperparameters: width, depth, number of training steps, weight decay, label smoothing and dropout. For each hyperparameter, there exists an optimal accuracy up to which improving accuracy improves PS. This optimum is fairly low and is attained quite early in the hyperparameter sweep. Beyond this point, improved classifier accuracy corresponds to worse PS.
As illustration, we present the variation of PS with respect to two hyperparameters: training steps in ResNets and width in ViTs. The PS of ResNet-50 and ResNet-200 peak very early at the first few epochs of training. After the peak, PS of better classifiers decrease more drastically. ResNets are trained with a learning rate schedule that causes a stepwise increase in accuracy as a function of training steps. Interestingly, after the peak, they also exhibit a step-wise decrease in PS that matches this step-wise accuracy increase.
Early-stopped ResNets attain the best PS across different depths of 6, 50 and 200.
{kind=link}
{kind=link}
ViTs consist of a stack of transformer blocks applied to the input image. The width of a ViT model is the number of output neurons of a single transformer block. Increasing its width is an effective way to improve its accuracy. Here, we vary the width of two ViT variants, B/8 and L/4 (i.e., Base and Large ViT models with patch sizes 4 and 8 respectively), and evaluate both the accuracy and PS. Similar to our observations with early-stopped ResNets, narrower ViTs with lower accuracies perform better than the default widths. Surprisingly, the optimal width of ViT-B/8 and ViT-L/4 are 6 and 12% of their default widths. For a more comprehensive list of experiments involving other hyperparameters such as width, depth, number of training steps, weight decay, label smoothing and dropout across both ResNets and ViTs, check out our paper.
Narrow ViTs attain the best PS.
{kind=link}
{kind=link}
Scaling Down Models Improves Perceptual Scores
Our results prescribe a simple strategy to improve an architecture’s PS: scale down the model to reduce its accuracy until it attains the optimal perceptual score. The table below summarizes the improvements in PS obtained by scaling down each model across every hyperparameter. Except for ViT-L/4, early stopping yields the highest improvement in PS, regardless of architecture. In addition, early stopping is the most efficient strategy as there is no need for an expensive grid search.
Model Default Width Depth Weight
Decay Central
Crop Train
Steps Best ResNet-6 69.1 +0.4 – +0.3 0.0 +0.5 69.6 ResNet-50 68.2 +0.4 – +0.7 +0.7 +1.5 69.7 ResNet-200 67.6 +0.2 – +1.3 +1.2 +1.9 69.5 ViT B/8 67.6 +1.1 +1.0 +1.3 +0.9 +1.1 68.9 ViT L/4 67.9 +0.4 +0.4 -0.1 -1.1 +0.5 68.4 Perceptual Score improves by scaling down ImageNet models. Each value denotes the improvement obtained by scaling down a model across a given hyperparameter over the model with default hyperparameters.
Global Perceptual Functions
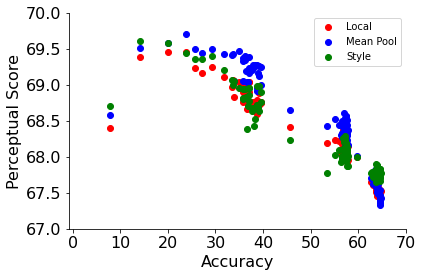
In prior work, the perceptual similarity function was computed using Euclidean distances across the spatial dimensions of the image. This assumes a direct correspondence between pixels, which may not hold for warped, translated or rotated images. Instead, we adopt two perceptual functions that rely on global representations of images, namely the style-loss function from the Neural Style Transfer work that captures stylistic similarity between two images, and a normalized mean pool distance function. The style-loss function compares the inter-channel cross-correlation matrix between two images while the mean pool function compares the spatially averaged global representations.
Global perceptual functions consistently improve PS across both networks trained with default hyperparameters (top) and ResNet-200 as a function of train epochs (bottom).
{kind=link}
{kind=link}
We probe a number of hypotheses to explain the relationship between accuracy and PS and come away with a few additional insights. For example, the accuracy of models without commonly used skip-connections also inversely correlate with PS, and layers close to the input on average have lower PS as compared to layers close to the output. For further exploration involving distortion sensitivity, ImageNet class granularity, and spatial frequency sensitivity, check out our paper.
Conclusion
In this paper, we explore the question of whether improving classification accuracy yields better perceptual metrics. We study the relationship between accuracy and PS on ResNets and ViTs across many different hyperparameters and observe that PS exhibits an inverse-U relationship with accuracy, where accuracy correlates with PS up to a certain point, and then exhibits an inverse-correlation. Finally, in our paper, we discuss in detail a number of explanations for the observed relationship between accuracy and PS, involving skip connections, global similarity functions, distortion sensitivity, layerwise perceptual scores, spatial frequency sensitivity and ImageNet class granularity. While the exact explanation for the observed tradeoff between ImageNet accuracy and perceptual similarity is a mystery, we are excited that our paper opens the door for further research in this area.
Acknowledgements
This is joint work with Neil Houlsby and Nal Kalchbrenner. We would additionally like to thank Basil Mustafa, Kevin Swersky, Simon Kornblith, Johannes Balle, Mike Mozer, Mohammad Norouzi and Jascha Sohl-Dickstein for useful discussions.