
Despite decades of research, we don’t see many mobile robots roaming our homes, offices, and streets. Real-world robot navigation in human-centric environments remains an unsolved problem. These challenging situations require safe and efficient navigation through tight spaces, such as squeezing between coffee tables and couches, maneuvering in tight corners, doorways, untidy rooms, and more. An equally critical requirement is to navigate in a manner that complies with unwritten social norms around people, for example, yielding at blind corners or staying at a comfortable distance. Google Research is committed to examining how advances in ML may enable us to overcome these obstacles.
In particular, Transformers models have achieved stunning advances across various data modalities in real-world machine learning (ML) problems. For example, multimodal architectures have enabled robots to leverage Transformer-based language models for high-level planning. Recent work that uses Transformers to encode robotic policies opens an exciting opportunity to use those architectures for real-world navigation. However, the on-robot deployment of massive Transformer-based controllers can be challenging due to the strict latency constraints for safety-critical mobile robots. The quadratic space and time complexity of the attention mechanism with respect to the input length is often prohibitively expensive, forcing researchers to trim Transformer-stacks at the cost of expressiveness.
As part of our ongoing exploration of ML advances for robotic products we partnered across Robotics at Google and Everyday Robots to present “Learning Model Predictive Controllers with Real-Time Attention for Real-World Navigation” at the Conference on Robot Learning (CoRL 2022). Here, we introduce Performer-MPC, an end-to-end learnable robotic system that combines (1) a JAX-based differentiable model predictive controller (MPC) that back-propagates gradients to its cost function parameters, (2) Transformer-based encodings of the context (e.g., occupancy grids for navigation tasks) that represent the MPC cost function and adapt the MPC to complex social scenarios without hand-coded rules, and (3) Performer architectures: scalable low-rank implicit-attention Transformers with linear space and time complexity attention modules for efficient on-robot deployment (providing 8ms on-robot latency). We demonstrate that Performer-MPC can generalize across different environments to help robots navigate tight spaces while demonstrating socially acceptable behaviors.
Performer-MPC
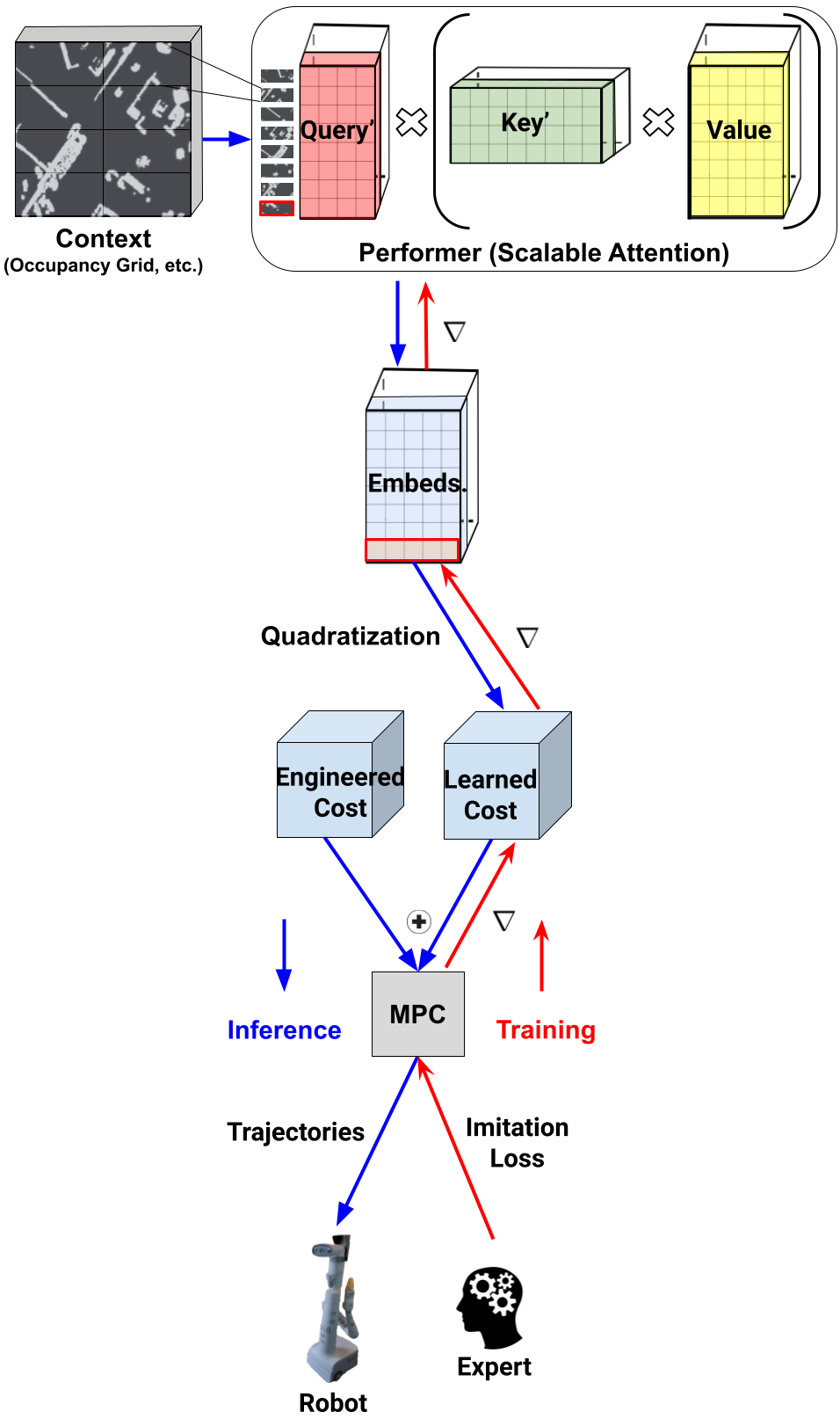
Performer-MPC aims to blend classic MPCs with ML via their learnable cost functions. Thus Performer-MPCs can be thought of as an instantiation of the inverse reinforcement learning algorithms, where the cost function is inferred by learning from expert demonstrations. Critically, the learnable component of the cost function is parameterized by latent embeddings produced by the Performer-Transformer. The linear inference provided by Performers is a gateway to on-robot deployment in real time.
In practice, the occupancy grid provided by fusing the robot’s sensors serves as an input to the Vision Performer model. This model never explicitly materializes the attention matrix, but rather leverages its low-rank decomposition for efficient linear computation of the attention module, resulting in scalable attention. Then, the embedding of the particular fixed input-patch token from the last layer of the model parameterizes the quadratic, learnable part of the MPC model’s cost function. That part is added to the regular hand-engineered cost (distance from the obstacles, penalty-terms for sudden velocity changes, etc.). The system is trained end-to-end via imitation learning to mimic expert demonstrations.
Performer-MPC overview. The final latent embedding of the patch highlighted in red is used to construct context dependent learnable cost. The backpropagation (red arrows) is through the parameters of the Transformer. Performer provides scalable attention module computation via low-rank approximate decomposition of the regular attention matrix (matrices Query’ and Key’) and by changing the order of matrix multiplications (indicated by the black brackets).
{kind=link}
Real-world robot navigation
Although, in principle, Performer-MPC can be applied in various robotic settings, we evaluate its performance on navigation in confined spaces with the potential presence of people. We deployed Performer-MPC on a differential wheeled robot that has a 3D LiDAR camera in the front and depth sensors mounted on its head. Our robot-deployable 8ms-latency Performer-MPC has 8.3M Performer parameters. The actual time of a single Performer run is about 1ms and we use the fastest Performer-ReLU variant.
We compare Performer-MPC with two baselines, a regular MPC policy (RMPC) without the learned cost components, and an Explicit Policy (EP) that predicts a reference and goal state using the same Performer architecture, but without being coupled to the MPC structure. We evaluate Performer-MPC in a simulation and in three real world scenarios. For each scenario, the learned policies (EP and Performer-MPC) are trained with scenario-specific demonstrations.
Experiment Scenarios: (a) Learning to avoid local minima during doorway traversal, (b) maneuvering through highly constrained spaces, (c) enabling socially compliant behaviors for blind corner, and (d) pedestrian obstruction interactions.
{kind=link}
Our policies are trained through behavior cloning with a few hours of human-controlled robot navigation data in the real world. For more data collection details, see the paper. We visualize the planning results of Performer-MPC (green) and RMPC (red) along with expert demonstrations (gray) in the top half and the train and test curves in the bottom half of the following two figures. To measure the distance between the robot trajectory and the expert trajectory, we use Hausdorff distance.
Top: Visualization of test examples in the doorway traversal (left) and highly constrained obstacle course (right). Performer-MPC trajectories aiming at the goal are always closer to the expert demonstrations compared to the RMPC trajectories. Bottom: Train and test curves, where the vertical axis represents Hausdorff distance and horizontal axis represents training steps.Top: Visualization of test examples in the blind corner (left) and pedestrian obstruction (right) scenarios. Performer-MPC trajectories aiming at the goal are always closer to the expert demonstrations compared to the RMPC trajectories. Bottom: Train and test curves, where the vertical axis represents Hausdorff distance and horizontal axis represents training steps.
{kind=link}
{kind=link}
Learning to avoid local minima
We evaluate Performer-MPC in a simulated doorway traversal scenario in which 100 start and goal pairs are randomly sampled from opposing sides of the wall. A planner, guided by a greedy cost function, often leads the robot to a local minimum (i.e., getting stuck at the closest point to the goal on the other side of the wall). Performer-MPC learns a cost function that steers the robot to pass the doorway, even if it must veer away from the goal and travel further. Performer-MPC shows a success rate of 86% compared to RMPC’s 24%.
Comparison of the Performer-MPC with Regular MPC on the doorway passing task.
{kind=link}
Learning highly constrained maneuvers
Next, we test Performer-MPC in a challenging real-world scenario, where the robot must perform sharp, near-collision maneuvers in a cluttered home or office setting. A global planner provides coarse way points (a skeleton navigation path) that the robot follows. Each policy is run ten times and we report a success rate (SR) and an average completion percentage (CP) with variance (VAR) of navigating the obstacle course, where the robot is able to traverse without failure (collisions or getting stuck). Performer-MPC outperforms both RMPC and EP in SR and CP.
An obstacle course with policy trajectories and failure locations (indicated by crosses) for RMPC, EP, and Performer-MPC.An Everyday Robots helper robot maneuvering through highly constrained spaces using Regular MPC, Explicit Policy, and Performer-MPC.
{kind=link}
{kind=link}
Learning to navigate in spaces with people
Going beyond static obstacles, we apply Performer-MPC to social robot navigation, where robots must navigate in a socially-acceptable manner for which cost functions are difficult to design. We consider two scenarios: (1) blind corners, where robots should avoid the inner side of a hallway corner in case a person suddenly appears, and (2) pedestrian obstruction, where a person unexpectedly impedes the robot’s prescribed path.
Performer-MPC deployed on an Everyday Robots helper robot. Left: Regular MPC efficiently cuts blind corners, forcing the person to move back. Right: Performer-MPC avoids cutting blind corners, enabling safe and socially acceptable navigation around people.Comparison with an Everyday Robots helper robot using Regular MPC, Explicit Policy, and Performer-MPC in unseen blind corners.Comparison with an Everyday Robots helper robot using Regular MPC, Explicit Policy, and Performer-MPC in unseen pedestrian obstruction scenarios.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Conclusion
We introduce Performer-MPC, an end-to-end learnable robotic system that combines several mechanisms to enable real-world, robust, and adaptive robot navigation with real-time, on-robot transformers. This work shows that scalable Transformer-architectures play a critical role in designing expressive attention-based robotic controllers. We demonstrate that real-time millisecond-latency inference is feasible for policies leveraging Transformers with a few million parameters. Furthermore, we show that such policies enable robots to learn efficient and socially acceptable behaviors that can generalize well. We believe this opens an exciting new chapter on applying Transformers to real-world robotics and look forward to continuing our research with Everyday Robots helper robots.
Acknowledgements
Special thanks to Xuesu Xiao for co-leading this effort at Everyday Robots as a Visiting Researcher. This research was done by Xuesu Xiao, Tingnan Zhang, Krzysztof Choromanski, Edward Lee, Anthony Francis, Jake Varley, Stephen Tu, Sumeet Singh, Peng Xu, Fei Xia, Sven Mikael Persson, Dmitry Kalashnikov, Leila Takayama, Roy Frostig, Jie Tan, Carolina Parada and Vikas Sindhwani. Special thanks to Vincent Vanhoucke for his feedback on the manuscript.